Python是一款功能强大的计算机程序语言,同时也可以被看做是一款面向对象的通用型语言。它的功能特点比较突出,极大的方便开发人员应用。在这里我们先来一起了解一下有关Python市县网页爬虫的方法。
今天看到一个网页,又因为在家里用电话线上网,一直在线阅读很麻烦。所以就写了个简单的程序把网页抓下来离线阅读,省点电话费:)这个程序因为主页面链接到的页面都在同一个目录下,结构很简单,只有一层。因此写了一些硬编码做链接地址的分析。
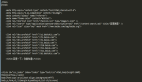
Python实现网页爬虫代码如下:
- #!/usr/bin/env python
- # -*- coding: GBK -*-
- import urllib
- from sgmllib import SGMLParser
- class URLLister(SGMLParser):
- def reset(self):
- SGMLParser.reset(self)
- self.urls = []
- def start_a(self, attrs):
- href = [v for k, v in attrs if k == 'href']
- if href:
- self.urls.extend(href)
- url = r'http://www.sinc.sunysb.edu/Clubs/buddhism/JinGangJingShuoShenMo/'
- sock = urllib.urlopen(url)
- htmlSource = sock.read()
- sock.close()
- #print htmlSource
- f = file('jingangjing.html', 'w')
- f.write(htmlSource)
- f.close()
- mypath = r'http://www.sinc.sunysb.edu/Clubs/buddhism/JinGangJingShuoShenMo/'
- parser = URLLister()
- parser.feed(htmlSource)
- for url in parser.urls:
- myurl = mypath + url
- print "get: " + myurl
- sock2 = urllib.urlopen(myurl)
- html2 = sock2.read()
- sock2.close()
- # 保存到文件
- print "save as: " + url
- f2 = file(url, 'w')
- f2.write(html2)
- f2.close()
以上就是我们为大家介绍的有关Python实现网页爬虫的实现方法。
【编辑推荐】