












Python语言这同时说明IDLE的Shell支持两种格式的中文字符串:GBK编码的“str”对象,和UNICODE编码的unicode对象,我连接的时候也用的是UTF-8,为什么查询得到的文本内容却是UNICODE编码(unicode对象)?这是MySQLdb库的设置么?
在window下面用记事本编辑文件的时候,如果保存为UNICODE或UTF-8,分别会在文件的开头加上两个字节“\xFF\xFE”和三个字节“\xEF\xBB\xBF”。在读取的时候就可能会遇到问题,但是不同的环境对这几个多于字符的处理也不一样。
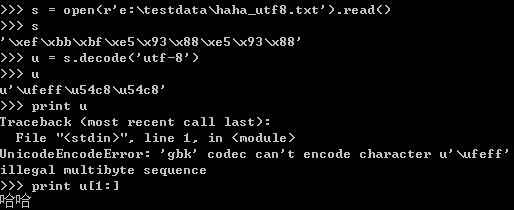
打开utf-8格式的文件并读取utf-8字符串后,解码变成unicode对象。但是会把附加的三个字符同样进行转换,变成一个unicode字符,字符的数据值为“\xFF\xFE”。这个字符不能被打印。编码的时候需要跳过这个字符。
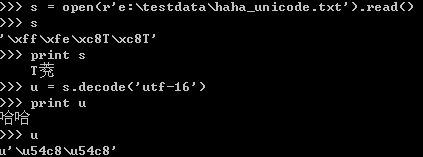
打开unicode格式的文件后,得到的字符串正确。这时候适用utf-16解码,能得到正确的unicdoe对象,可以直接使用。多余的那个填充字符在进行转换时会被过滤掉。

开ansi格式的文件后,没有填充字符,可以直接使用,结论:读写使用python生成的文件没有任何问题,但是在处理由notepad生成的文本文件时,如果该文件可能是非ansi编码,需要考虑如何处理填充字符。
刚刚接触Python语言,我用的数据库是mysql。在执行插入、查找等操作时,如果运行环境使用的字符编码和mysql不一致,就可能导致运行时的错误。当然,和上面看到的情况一样。
运行环境并不是关键因素,关键是查询语句的编码方式。如果在每次执行查询操作时都把查询字符串做一次编码转换,转变成mysql的默认字符编码,一样不会遇到问题。但是这样写代码也太痛苦了吧。
相面是两种方法的用法比较:

另外,在Python语言的shell中,不要用 u’中文’ 对属性进行赋值。上面讨论过,这样得到的unicode字符串不正确。
【编辑推荐】










