













Oracle数据库机Exadata自推出以后,因为在减小带宽占用,快速检索等方面的优势而备受业界关注。但是对于具体的技术细节,很多数据库运维人员并不是很了解。
本文转载自支付宝架构师冯大辉的博客
原文链接:http://www.dbanotes.net/database/oracle_exadata.html
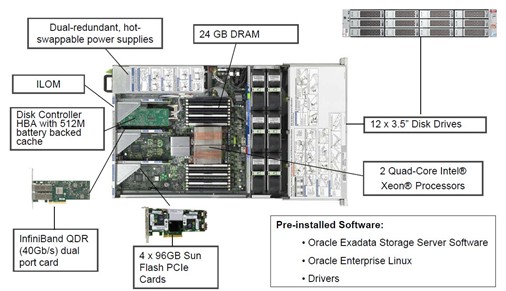
自从 Oracle 和HP 推出Exadata 之后,我就很关注这个产品,之前也写了一篇Oracle Database Machine介绍它。去年,Oracle和SUN合并后,推出了Oracle Exadata V2,相比较上一代产品有几个变化:第一,使用SUN的硬件;第二,宣称支持OLTP应用;第三,Oracle 11g R2 提供了更多的新特性。Exadata Smart Flash Cache
Exadata V2整体架构并没有太多改变,换用了SUN的硬件,除了采用Intel最新的Nehalem CPU 以外,每台Storage Cell 更是配置了384GB 的Flash,这也是为什么V2 可以支持OLTP 应用的关键。
Flash Cache 完全是自动管理,Oracle会根据数据的访问情况,决定哪些数据放在 Flash Cache中。所有的数据都是先被写到普通磁盘上,再根据访问情况读入Flash Cache的,所以如果 Flash Card 发生故障,数据不会丢失。当然,Oracle提供了方式,可以让用户手动将表或者索引Pin 在 Flash Cache 中。
在自动管理的方式之外,Oracle还允许用户人工创建flash disks,和普通磁盘一样,这些Flash Disks通过ASM输出给数据库使用,用户可以把一些访问非常频繁的数据文件放在上面。这些 Flash Disks 不仅仅是Cache了,所以 ASM 会在Cell和Cell之间做镜像。如果某块卡发生故障,那么整个Storage Cell上的Flash Disks会offline,保证数据不会丢失。
Smart Scan
Smart Scan是 Exadata最重要的一个功能,它的作用就是把SQL 放在每个Cell 上去运行,然后每个Cell只返回符合条件的数据给数据库,这样就极大的降低了数据库服务器的负载和网络流量,并充分利用了Cell的计算资源和IO资源。
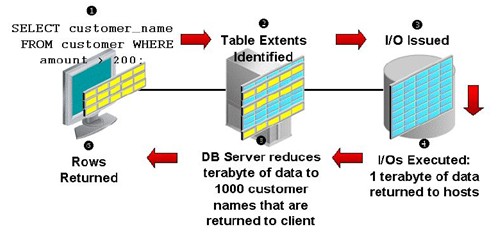
传统方式:所有的数据都需要返回给数据库服务器,网络带宽要求高,所有的计算在数据库服务器上完成。
Smart scan:只返回符合条件的数据,减少网络带宽,并充分利用了Cell 上的计算和IO资源。
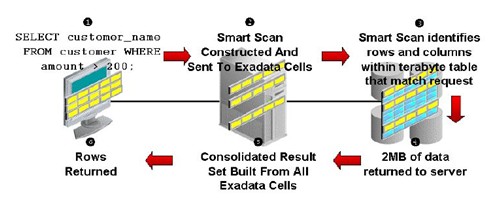
这里有一点要注意,在使用Smart Scan 时,每个Cell返回给DB Server的是结果集,而不再是传统的Block, DB Server 完成结果集的处理,并返回给客户端。
Smart Scan 如何处理 Join ?
这是我一直想要搞清楚的问题。事实上, Smart Scan 只能处理Join filtering,而真正Join的工作必须在DB Server上完成,而且Smart Scan 仅适合于处理 DSS 环境的复杂Join,对于 OLTP 类型的简单Join,Smart Scan 并不能发挥其优势。设想下面的查询:
select e.ename,d.dname from emp e, dept d where and e.ename='Jacky' and e.deptno=d.deptno;
- 1.
假设采用nested loops join,Smart Scan 只能完成 e.ename='Jacky' 这个条件的过滤,然后将符合条件的 emp 表的数据返回到 DB server,然后由 DB Server 完成 join 的工作,逐条查询dept表 (e.deptno=d.deptno) 的数据。所以Smart Scan 并不适合nested loop join(我认为 Smart Scan 只有在适合的条件下才会启用),只有 DSS 环境的大数据量复杂join才会发挥出优势。而且 Smart Scan 只能完成filtering的工作,而不能真正完成Join 的工作,这个与Greenplum 数据库是不同的(有兴趣可以看我的文章,Greenplum技术浅析)。设想下面的查询(emp和dept都是大表):
select e.ename,d.dname from emp e, dept d where e.deptno=d.deptno;
- 1.
假设采用Hash Join ,由于没有任何过滤条件,Smart Scan只能把两个表的数据全部返回到DB Server 上进行join操作,不过Smart Scan也不是一点用都没有,至少还可以进行column 的过滤,只返回需要的字段就可以了。
Oracle的文档中,曾经提到对于一个大表和小表join时,Smart Scan会采用bloom filter来快速定位(可以看我以前的文章,有趣的bloom filter )。方法是把小表build成为bloom filter,然后在每个storage cell上对大表做scan,利用bloom filter快速定位符合条件的结果,并返回给DB Server 作 join。
Storage Index
存储索引,顾名思义是在存储级别建立的索引,简单的说就是为表中的每一列数据建立一个索引,每个index entry记录一段数据区间的最大值,最小值以及它们的物理位置,文档上说1MB数据对应一条index entry,见下图:

如果我们查询B<2,或者B>8的数据,根据存储索引,我们就可以跳过这些不在min和max之间的数据块,极大的提高了扫描的速度,这就是存储索引的意义。
Hybrid Columnar Compress
首先我们要搞清楚,什么是行压缩,什么叫列压缩。我们熟悉的数据库,如Oracle、MySQL等都是基于行的数据库,就是行的不同字段物理上存放在一起,还有一种是基于列的数据库,就是每个字段的不同行物理上存放在一起。他们的优缺点同样突出:
基于行的数据库,访问一行非常方便,但是由于同一列的数据是分开存放的,如果要针对某一列进行查询时,几乎要扫描整个表才能得到结果。基于行数据库的压缩,称为行压缩。
基于列的数据库,因为同一列的数据物理上放在一起,所以访问一列非常方便,也就是说如果针对某一列进行查询时,不需要扫描整个表,只需要扫描这一列的数据就可以了,但是访问一行的全部字段非常不方便(又是废话)。基于列数据库的压缩,称为列压缩。
Oracle 通常说的 compress 功能(包括11g R2的Advanced compress),都是行压缩,因为Oracle是个基于行的数据库。大概的方法就是在block头部存放一个symbol table,然后将相同的值放在那里,每行上相同的数据指向symbol table,以此来达到压缩的目的。行压缩的效果通常不好,因为我们知道行与行之间,其实相同的数据并不多。但是列压缩则不同,因为相同列的数据类型相同,很容易达到很好的压缩效果。
行压缩和列压缩都有其优缺点,而Oracle的混合列压缩技术,实际上是融合了列压缩的高压缩比和行数据库的访问特性,将两者的优点结合起来。Oracle提出了 CU 的概念(compress unit),在一个 CU 内,是一个基于列的存储方式,采用列压缩,但是一个 CU 内保存了行的所有字段信息,所以在CU与CU之间,Oracle还是一个基于行的数据库,访问某一行,总是只在一个 CU 内(一个CU总是在一个block内)。

所以说混合列压缩,结合了列压缩和行访问的特点,即可以提供非常高的压缩率,又很好的保证了基于行类型的访问。
Exadata的另一个重要功能是IO resource management,如果我们在一个Exadata上部署了很多个数据库,可以用它来管理IO资源,这里就不作阐述了。
目前,我还没有了解到在国内有Exadata的应用,而且资料也是比较少的。希望有机会可以真实的测试一下它的性能,我不怀疑他在 DSS 环境下的表现,但是对于OLTP类型的应用,是否真的象Oracle说的那么强劲,还有待于验证。
【编辑推荐】
- 甲骨文与Sun推出新一代Exadata数据库产品
- Oracle数据库备份与恢复特性浅谈
- Oracle数据库调试与性能优化
- Oracle 11g R2的四个新增小特性总结
- Oracle中最易忽视的两个重要进程











