通常,当我们的MySQL数据库逐渐变慢时,我们就希望通过一切努力使它变得更快、更强、更大、更好!那么都有哪些方法呢?别着急,我会一个一个给大家介绍如何才能实现这些美好的愿望。阅读本系列文章将有助于扩大你的视野,更好地规划你将来的需要,本系列的第一篇文章“更快,更强的MySQL”讨论了查询优化和硬件调整,包括增加额外的服务器和应用程序变更,本文将介绍如何通过分区和负载均衡解决方案让你的MySQL变得更大更好。
更大的MySQL
增加更多的MySQL实例是提高应用程序响应速度的有效方法,如果你的服务器有多颗CPU,充足的内存和快速的硬盘,这些资源有相当一部分处于闲置状态,那么在这种情况下,在服务器上可以同时运行多个MySQL实例,因为MySQL默认情况下只有一个进程和多个会话线程,因此它真正能利用的最大硬件资源是有限的。
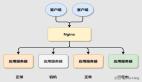
如果你的服务器已经快饱和了,那么必须增加服务器,不管你的多个MySQL实例是在一台服务器上,还是在多台服务器上,你都需要为应用程序配置一个方法让它知道该将查询发送给哪台服务器,如果是要修改数据,那就应该将指令发送到主数据库实例,如果仅仅是查询操作,那么随便发给任何一个从数据库实例即可。
1、数据分区和水平分区
因为许多Web应用程序是通过会话来识别用户的,通过会话将它们分配到不同的从数据库实例显得很有道理。例如A-G,H-O,P-Z数据库实例可能在工作,这时可以通过用户名的哈希值,或userid将用户分配到不同的服务器上,这就是所谓的分区键,选择分区键时需要慎重决定,因为它会影响到你如何构建从数据库实例,主要是考虑如何让这些服务器平均承担工作负载,如果选择得不好,假设从数据库倒掉,也可能会引起数据中断。
如果正采用这种分区,你需要决定程序运行时使用哪个数据库,这可以通过一个中间层如MySQL代理来实现,虽然它还处于Alpha阶段,但它的思想很好,并且已经有很多人将其用于生产环境,它运行在服务器上,响应端口3306上的请求,然后将这些查询通过高速语言如lua实现的某些逻辑转发给后端适当的服务器。
其次你也可以在应用程序中指定将查询发到哪些服务器,这也是最灵活的方法,你可以完全控制整个决策过程,你也可以使用master_pos_wait检查从数据库实例,看看它们是否有足够的计算资源。还有你使用的编程语言或Web框架可能也会提供这方面的支持,如果你还不清楚,可以查询它们的文档。
你还可以研究一下Continuent Tungsten,DBIx::DBCluster for Perl以及SQLRelay,它们支持许多不同的编程语言和数据库。同样,CMS如Drupal也支持多种只读的从数据库,你只需要启用这个功能即可。
使用这种架构需要考虑的另一个事情是,是否要使用主数据库实例,以及何时使用,一般说来,所有插入,更新和删除操作都应放在主数据库实例上完成,所有的查询操作都放在从数据库实例上完成。例如,如果某个用户对博客文章发表了注释,此时如果直接使用从数据库,可能无法完成,因为MySQL复制架构会存在滞后,此时从数据库中可能还没有那篇博文。
检查过时数据是一个更好的方法,如果你有报告查询在夜间运行,这种方法可能工作得很好,你只需要确保复制赶得上进度即可。
另一个方法是通过版本号跟踪数据库变更,在读取数据之前确定数据是否是最新的版本。
最后,MySQL提供了一个函数master_pos_wait,它可以确定从数据库更新到哪个时间点了。
2、功能分区
你可能已经使用到功能分区,使用功能分区时,需要创建一个生产数据库的副本用于不同目的,如其中一个用于数据仓库和报告,另一个用于文本搜索等。
通过负载均衡使MySQL变得更好
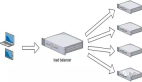
如果你的从数据库已经有些只读数据,你可能需要实现负载均衡,将流量平均分配到各个从数据库,实现方法有多种,如随机分配,最少连接法,响应速度最快法,或某种加权平均法,虽然某些硬件负载均衡设备可以提供负载均衡功能,但它们往往是设计用于均衡网络流量,并没有提供数据库相关的均衡功能。
幸运的是有很多软件解决方案,LVS项目就是一个不错的候选,它已经发展得相当成熟稳定,它提供了类似DNS轮询的负载均衡算法,但是在IP层实现的,速度非常快。此外,也有很多项目是建立在LVS基础之上的,包括wackamole,它是基于对等网络的,因此不会发生单点故障,还有一个值得推荐的项目是ultramonkey。
小结
MySQL提供了许多高级特性可以实现无限制的规模扩展,视不同应用环境有不同的最佳解决方案,因此需要在用于生产数据库之前,最好先对各种解决方案进行充分了解,并尽量搭建与生产环境负载相当的测试平台进行测试。
【编辑推荐】