Oracle经过长时间的发展,很多用户都很了解Oracle全表扫描了,这里我发表一下个人理解,和大家讨论讨论。优化器在形成执行计划时需要做的一个重要选择是如何从数据库查询出需要的数据。对于SQL语句存取的任何表中的任何行,可能存在许多存取路径(存取方法),通过它们可以定位和查询出需要的数据。优化器选择其中自认为是最优化的路径。
在物理层,Oracle读取数据,一次读取的最小单位为数据库块(由多个连续的操作系统块组成),一次读取的最大值由操作系统一次I/O的最大值与multiblock参数共同决定,所以即使只需要一行数据,也是将该行所在的数据库块读入内存。逻辑上,Oracle用如下存取方法访问数据:
Oracle全表扫描(Full Table Scans, FTS)
为实现Oracle全表扫描,Oracle读取表中所有的行,并检查每一行是否满足语句的WHERE限制条件。Oracle顺序地读取分配给表的每个数据块,直到读到表的最高水线处(high water mark, HWM,标识表的最后一个数据块)。一个多块读操作可以使一次I/O能读取多块数据块(db_block_multiblock_read_count参数设定),而不是只读取一个数据块,这极大的减少了I/O总次数,提高了系统的吞吐量,所以利用多块读的方法可以十分高效地实现Oracle全表扫描,而且只有在Oracle全表扫描的情况下才能使用多块读操作。在这种访问模式下,每个数据块只被读一次。由于HWM标识最后一块被读入的数据,而delete操作不影响HWM值,所以一个表的所有数据被delete后,其Oracle全表扫描的时间不会有改善,一般我们需要使用truncate命令来使HWM值归为0。幸运的是Oracle 10G后,可以人工收缩HWM的值。
由FTS模式读入的数据被放到高速缓存的Least Recently Used (LRU)列表的尾部,这样可以使其快速交换出内存,从而不使内存重要的数据被交换出内存。
使用FTS的前提条件:在较大的表上不建议使用Oracle全表扫描,除非取出数据的比较多,超过总量的5% -- 10%,或你想使用并行查询功能时。
使用Oracle全表扫描的例子:
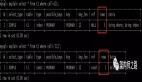
- explain plan for select * from dual;
- Query Plan
- SELECT STATEMENT [CHOOSE] Cost=
- TABLE ACCESS FULL DUAL
行的ROWID指出了该行所在的数据文件、数据块以及行在该块中的位置,所以通过ROWID来存取数据可以快速定位到目标数据上,是Oracle存取单行数据的最快方法。
为了通过ROWID存取表,Oracle 首先要获取被选择行的ROWID,或者从语句的WHERE子句中得到,或者通过表的一个或多个索引的索引扫描得到。Oracle然后以得到的ROWID为依据定位每个被选择的行。
这种存取方法不会用到多块读操作,一次I/O只能读取一个数据块。我们会经常在执行计划中看到该存取方法,如通过索引查询数据。
使用ROWID存取的方法:
- explain plan for select * from dept where rowid = 'AAAAyGAADAAAAATAAF';
- Query Plan
- SELECT STATEMENT [CHOOSE] Cost=1
- TABLE ACCESS BY ROWID DEPT [ANALYZED]
【编辑推荐】