













Java开发2.0?听起来是个挺新颖,但也挺老调长谈的概念。随着云计算的兴起,而Google App Engine又提供了Java支持,IBMDW的Andrew Glover在本文中将介绍这个Java开发2.0是怎么一回事,以及在Google App Engine中又是如何体现的。
Java 世界如同一个丰富的生态系统,涉及开发人员、事务以及(最为重要的)应用程序等各种角色,其中大部分内容在过去十年里已经发展成熟。全球 Java 社区在 Java 平台上投入了巨大的金钱、时间和脑力劳动,这些贡献造就了一个包含成功的开源商业工具、框架以及解决方案的巨大宝库。
在 Java 平台方面的各种投入使 Java 开发的方式产生了微妙的变化。两个重要的趋势正在快速改变 Java 开发的特征:
- 充分地利用开源工具和框架自上而下 构建应用程序
- 租用(或外借)各种应用程序基础设施来管理软件生命周期,包括运行应用程序本身
我所指的 Java开发2.0 的任何一个方面都不是新的或革命性的改变,仅仅是实现技术已经成熟到可以快速、便宜地组装更好的应用程序,这在 Java 技术的历史上是从未有过的 — 这是全世界都希望实现的主要业务需求之一。
本文开启了一个崭新的系列,将深入讨论 Java开发2.0。您将了解以下内容:使用 Amazon EC2 构建和部署 Web 应用程序、使用 Google 的 App Engine、利用 CouchDB(被称为 Web 的数据库),以及在短期内以目前为止最低的成本组装、测试和部署应用程序的工具和技术。
第一站:Google App Engine for Java。我将通过常用的 “Hello World” 方法来介绍这个平台,然后展示如何使用 Groovy、Java Data Objects (JDO) 和 Eclipse plug-in for Google App Engine 来创建一个有效的 Web 应用程序。但是,在此之前,让我们先快速了解一下 Java开发2.0 的商业价值。
速度快成本低
快速和便宜以前很少会和 Java 开发联系在一起。事实上,它们常常让人联想到不太严肃的软件开发 — 只有有限资源的小型企业进行的开发。然而,事实的真相就是,IT 对于许多公司(不论大公司还是小公司)都是一个成本中心,这促使企业在最大程度获取价值的同时降低 IT 成本。
这就是 Java 开发 2.0 发挥作用的舞台。通过利用开源工具、框架甚至是解决方案,企业可以快速地组装应用程序,因为企业自身不需要编写大量代码。当我在十多年前第一次开始使用 Java 技术进行开发时,可供开发人员选择的工具和框架非常有限。并且这些有限的工具还不是免费的。您必须购买一个 IDE、一个数据库、一个对象-关系映射(ORM)框架(最糟的是,可能必须购买一个驱动程序才能与数据库通信),当然,还需要购买在其上部署应用程序的机器。那么现在呢?我刚刚列出的所有(以及更多)内容都可以免费获得,并且具有很棒的品质。
此外,通过借用基础设施(比如 Amazon EC2 或 Google App Engine 提供的基础设施),您可以以非常低的成本部署应用程序(您以前需要购买所需的基础设施)。
构建、购买还是借用:这是个新问题
许多企业为运行应用程序,比如数据库、应用服务器、变更管理系统和缺陷跟踪工具,准备了一个硬件清单。但是,在现在这个时代,这个清单完全可以扔掉,取而代之的是在其他人的基础设施上以运行服务的形式使用相同的软件包。
团队用来管理开发流程的全部应用程序堆栈都可以外借 — 也就是说,花费少量的费用租用 — 这样公司就不需要再购买运行应用程序所需的硬件。例如,不需要购买机器来运行变更管理系统(比如 Subversion 或 Git,两者都是开源的免费产品),团队可以使用 GitHub 之类的共享变更管理服务。出租 GitHub 的企业引入了硬件资产成本,因此需要向使用 Git 的其他组织收取少量费用(通常为每用户每月收取)。从其他提供商以服务形式租用软件的原理可以应用于缺陷跟踪、测试用例管理和需求管理(比如,通过 Hosted JIRA 或 Pivotal Tracker)。
相同的原理可以应用于运行其他软件平台的底层硬件资产(通常为定制的)。企业可以放弃针对特定 Web 应用程序的底层硬件,而倾向于在由 Amazon、Google 或该领域的其他竞争者提供的硬件上运行应用程序。这些企业提供了以不同程度租用 硬件的能力,这足以托管应用程序。并且,这些公司还可以管理可伸缩性、备份甚至安全性。想一下:Amazon 和 Google 许久之前就解决了这些(以及更多)问题,现在它们更加擅长处理并创新高效运行软件平台的方面(这是真的,面对事实吧)。
例如,通过使用 Google 的 App Engine,一家 IT 公司就可以降低购买基础设施以运行所需应用程序的总体成本。并且可以更加快速地部署这些应用程序,因为已经考虑并提出了各种与应用程序部署和管理有关的交叉问题(并且很可能以一种完美的方式)。
快速 和便宜 不再意味着劣质。相反,Java 开发 2.0 是一种战略性方法,已经设想了一个以质量为重点的可靠流程。
#p#
使用 Google App Engine 减轻负担
Google App Engine 是一个可以在 Google 的昂贵基础设施上构建和部署 Java(和 Python)Web 应用程序的真正平台。无需任何许可费用(当然,除非您选择在基础设施上使用的软件库要求拥有一个许可)、无需为带宽或存储空间支付前期成本。App Engine 基础设施在最初是完全免费的,直到您达到了一个使用阈值 — 500MB 的存储空间,引述 Google 的话,“为每个月大约 500 万的页面浏览提供足够的 CPU 和带宽”。可以这样说,一旦您达到了 Google 开始收费的那个点,您的 Web 应用程序已经很明显地产生了巨大的通信量(以及利益)。
启动并运行 App Engine 再简单不过了。Google 甚至提供了一个 Eclipse 插件,可以为您处理几乎任何事情。并且该插件包含 “Hello World” servlet 应用程序的基本组件,该应用程序可以帮助您开始了解此平台。在其最近一篇 developerWorks 文章(“Google App Engine for Java:第 1 部分:运转起来!” 中,Rick Hightower 向您介绍了部署 Hello World 应用程序(包含屏幕快照)的整个过程。如果您还没有阅读 Rick 的文章,那么可以遵循下面的步骤:
- 创建一个 Google App Engine 帐户(是免费的),方法是在 http://code.google.com/appengine/ 中单击 Getting Started 下的 Sign up 链接。
- 从 http://code.google.com/appengine/downloads.html 下载 Google App Engine plug-in for Eclipse 并安装它。
- 在 Eclipse 中通过单击 New Web Application Project 按钮创建一个新项目;在显示的对话框中,不要勾选 Use Google Web Toolkit 选项。命名项目和您感兴趣的相应的包。
- 在层次结构中选择项目并单击 Deploy App Engine Project 按钮。
- 输入凭证(在步骤 1 中创建 App Engine 帐户时使用的内容)。
- 将本地项目与在最初创建 App Engine 帐户时生成的应用程序 ID 关联起来。(您最多可拥有 10 个 ID)。
- 单击 Deploy 按钮。将看到 Eclipse 控制台中闪过大量文本(插件在后台执行大量工作,包括增强那些利用 Google 的出色的数据存储服务所需的类)。当屏幕稳定后(并且一切工作正常),您应当会看到一条 “Deployment completed successfully” 消息。
- 访问在 Google 上的 App Engine 帐户页面并在 Google 指示板上找到 Versions 链接。您将看到自己的已部署的版本及对应的 URL。单击 URL,然后单击通向生成的 servlet 的链接,您会看到单调但令人欣慰的 “Hello, world” 纯文本。
使用 Groovlets 编写更少的代码
您已经成功部署了您的第一个 Google App Engine 应用程序,并且没有编写一行代码。事实上,如果计划利用 App Engine,您总是要编写一些代码的 — 但要记住,您可以重用已有的大量代码来更加轻松地 完成工作。这些可重用代码可能是 Google 提供的一些服务(比如其数据存储或 Google 帐户服务)或被移植到 Google 基础设施上的开源库。重用其他人的代码意味着您常常只需编写更少的代码 — 而更少的代码意味着更少的缺陷。
我最喜欢的开源库(以及平台)之一就是 Groovy,它总是可以生成更少的代码行来创建有效的应用程序。Groovy 团队最近发布了可以使用 App Engine 的平台版本,使您能够利用 Groovlets 而不是 servlets 来在短期内创建一个有效的应用程序。Groovlets 是一些在行为上类似 servlets 的简单 Groovy 脚本。由于您已经实现了一个可以输出 “Hello, world” 的 servlet,因此我将展示使用 Groovlet 完成同样的事情是多么地简单(您将看到 Groovy 可以减少多少代码)。
使用 Eclipse 插件在 App Engine 上部署 Groovlet 只需要很简单的一些步骤:
- 从 http://groovy.codehaus.org/Download 下载 Groovy 的最新模板(撰写本文时为 1.6.3 版本)。
- 找到 groovy-all-1.6.3.jar 并将它放到您的 App Engine 项目的 war/WEB-INF/lib 目录中。顺便说一句,在这个目录中,您可以放置应用程序所需的任何库(我将在稍后给出一些注意事项)。
- 将清单 1 中的内容(将 Groovlets 映射到指定的请求)添加到 war/WEB-INF 目录中的 web.xml 文件:
清单 1. 更新 web.xml 文件以支持 Groovlets< servlet> < servlet-name>GroovyServlet< /servlet-name> < servlet-class>groovy.servlet.GroovyServlet< /servlet-class> < /servlet> < servlet-mapping> < servlet-name>GroovyServlet< /servlet-name> < url-pattern>*.groovy< /url-pattern> < /servlet-mapping>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 将 groovy 目录添加到 WEB-INF 目录;这是保存 Groovlets 的位置。在 groovy 目录中,创建一个名为 helloworld.groovy 的新文件。在这个新文件中,输入
println "Hello, Groovy baby!" - 更新应用程序的版本(假设 1-1)并重新部署。通过 Google 指示板找到相应的 URL,然后在浏览器中打开 /helloworld.groovy,会看到 Groovy 在 Google 的基础设施上输出了一条 hip 消息。
非常简单,不是吗?您只需要添加 Groovy JAR、更新 web.xml 文件、创建一个新的 groovy 目录、编写一个 Groovlet 然后部署它。您是否还注意到 Groovlet 如何只使用一行代码 完成与默认 servlet 插件的工作?您希望编写并维护哪一个:一个庞大的类或是具有相同行为的很小的类?
Groovy + Java = 快速构建有效的应用程序
现在,我将展示如何结合使用 Groovy 和 Google 的 App Engine 快速创建一个有效的应用程序。我将使用一个简单的 HTTP 页面、一个 Groovlet 以及一个增强了 JDO 的 Java 类来持久化事件(在本例中为 triathlon)。我将在这里保持简单性,但是您将会看到这个应用程序可以不断演变来包括其他特性,并且在本系列后续文章中,您将实现这些特性(当然,使用不同的基础设施和技术)。
快速 JDO
Google App Engine 提供了使用 JDO 持久化数据的能力,JDO 是一个 Java 持久化标准。对于大部分 Java 开发人员来说,持久化数据常常意味着将信息保存到一个关系数据库中;然而,对于 Google 来讲,底层存储机制就是它的 Big Table,而后者并不是关系型的。也就是说,这一点无关紧要:Google 如何持久化特定属性的细节在很大程度上已经被隐藏。可以这样说,您可以使用普通的 Java 对象(或 Groovy 对象,就本文而言)来构建一个应用程序,这个应用程序可以像任何其他应用程序那样存储信息。这就是 Google 的方法,您必须使用 JDO。(Hibernate 无疑是面向 Java 的最流行的 ORM 框架,但它并不能用于 App Engine)。
JDO 非常简单。您将创建 POJO — 老式普通 Java 对象(可以和其他 Java 对象建立联系),您通过类级别的 @PersistenceCapable 注释将其声明为具有持久能力。通过 @Persistent 注释指定要进行持久化的对象的属性。例如,我希望存储 triathlon 事件(目前而言,我将关注事件而不是与 triathlon 有关的各种结果)— 就是说,事件拥有一个名称(triathlon 的名称),可能还有一个描述(triathlon 的类型)和一个日期。目前为止,我的 JDO 看上去类似清单 2:
|
无论使用哪一种底层机制(即关系型或 Google 的 Big Table),数据持久性始终需要涉及键(key)的概念:一种为了避免数据崩溃而确保数据的不同方面具有惟一性的方法。例如,对于 triathlon,它的键可以是 triathlon 的名称。如果两个 triathlon 拥有相同的名称,那么可以将名称和日期组合起来作为键。不管您使用何种方式通过 Google App Engine 和 JDO 表示键,必须通过 @PrimaryKey 注释在 JDO 对象中指定一个键。您还可以为键的生成方式选择一些策略 — 由您或 Google 生成。我将使用 Google 生成并保持简单性:我的 triathlon 对象的键被表示为一个普通的 Java Long 对象,并且我将通过指定一个值策略 来让 Google 确定实际的值。清单 3 添加了一个主键:
|
如清单 3 所示,我的 triathlon JDO 拥有一个由 Google 基础设施管理的键,并且添加了一些标准的方法(toString、hashCode 和 equals),为调试、登录以及适当的功能提供了极大的帮助。我并没有亲自编写这些内容,相反,我使用了 Apache commons-lang 库。我还添加了一个构造函数,与调用大量 setter 方法相比,这个构造函数可以更加轻松地创建完全初始化的对象。
我有意维持了 JDO 的简单性,但是正如您所见,并没有包含多少内容(就是说,为了保持简单性,我去掉了所有的关系并忽略了 getter 和 setter 方法)。您只需对域进行建模并随后使用一些注释来修饰模型,然后剩下的工作就由 Google 来完成。
将对象定义为具有持久性后,还剩下最后一个步骤。要与底层的数据存储交互,需要使用 PersistenceManager,这是一个 JDO 标准类,顾名思义,它的作用就是在一个底层数据存储中保存、更新、检索和删除对象(非常类似于 Hibernate 的 Session 对象)。这个类通过一个工厂(PersistenceManagerFactory)创建,这个工厂非常复杂;因此,Google 建议创建一个独立的对象来管理工厂的单个实例(后者在您需要时返回一个合适的 PersistenceManager)。相应地,我可以定义一个简单的独立对象来返回 PersistenceManager 的实例,如清单 4 所示:
PersistenceManager 实例的简单独立对象
|
可以看到,我的 PersistenceMgr 非常的简单。manufacture 方法从 PersistenceManagerFactory 的单个实例返回一个 PersistenceManager 实例。您还会注意到,清单 4 中没有出现任何特定于 Google 的代码或任何其他利用 JDO 的代码 — 所有引用都是指向标准 JDO 类和接口的。
新添加的两个 Java 对象位于我的项目的 src 目录中,并且我将 commons-lang 库添加到了 war/WEB-INF/lib 目录中。
利用定义好的简单 triathlon JDO POJO 和方便的 PersistenceMgr 对象,我已经有了很好的起点。我所需要的就是能够捕获 triathlon 信息。
#p#
大多数 Web 应用程序都遵循相同的模式:通过 HTML 表单捕捉信息,然后将它们提交到服务器端资源以进行处理。当然,这一过程中还混合了许多其他技术,但是不管底层技术或基础设施如何,模式始终保持不变。Google App Engine 也是如此 — 我已经编码了服务器端资源来处理保存的 triathlon 数据。剩下的工作就是捕捉信息 — 表单 — 以及将服务器端与表单连接起来。按 Model-View-Controller (MVC) 的话说,我需要一个控制器(通常为一个 servlet);我将利用 Groovlet 替代,因为我希望编写更少的代码。
我的 HTML 表单非常简单:我所需做的就是创建一个 HTML 页面,利用某些简单的 Cascading Style Sheets (CSS) 代码来创建表单,如图 1 所示,看上去更接近 Web 2.0,而不是 1998 年出现的 HTML 页面:
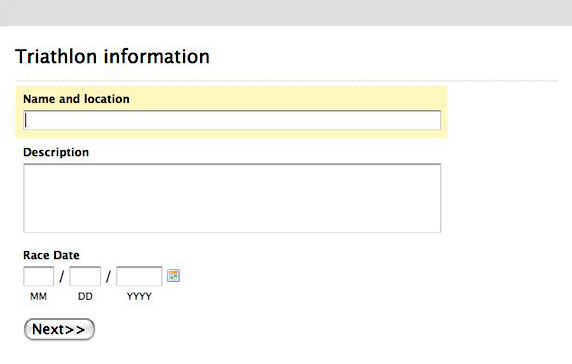
可以从图 1 中看到,表单捕捉到一个名称、描述和一个日期。然而,日期并不简单 — 它实际上是一个日期的三个属性。
快速 Groovlet
Groovlets 使得编写控制器变得非常简单:它们需要更少的代码并自动提供了所需的对象。在 Groovlet 中,您分别通过 request 和 response 对象隐式地访问 HTML 请求和响应。在我的 Groovlet 中,我可以通过 request.getParameter("name") 调用获得提交的 HTML 表单的所有属性,如清单 5 所示:
|
前面编写的 JDO 使用了一个 Java Date 对象;然而,在清单 5 中,我处理了 Date 的三个不同属性。因此我需要一个 DateFormat 对象来将 month、day、year 三者的组合转换为一个普通的 Java Date,如清单 6 所示:
|
最后,从已提交 HTML 表单获得所有参数后,我可以使用清单 7 的代码,通过我的 JDO 和清单4的 PersistenceMgr 对象将它们持久化到 Google 的基础设施中:
|
就是这么简单!当然,随着更多的页面加入到我的简单应用程序中(比如捕捉特定 triathlon 的结果),我可能需要转发或重定向到另一个表单,这将捕捉额外的信息,与向导十分类似。不管怎样,通过一些简短的代码片段,我快速组合了一个简单的 Web 应用程序,它可以通过 JDO(使用普通 Java 编码)和一个 Groovlet(当然,使用 Groovy 编码)将数据持久化到 Google 的基础设施中。部署应用程序非常简单,只需在 appengine-web.xml 文件中指定一个版本并单击 Deploy 按钮。
但是,这个用于捕捉 triathlon 事件的只包含一个表单的 Web 应用程序并没有试图实现全部的功能,所以说,我仅仅是将应用程序部署到一个不规则的、普遍存在的环境中。我不需要触发一个 Web 容器甚至指定在哪里 部署应用程序。(它位于 California、我的硬盘或者是月球上?)妙处在于这并不重要 — Google 负责处理这个问题。注意,是解决所有问题。此外,可以肯定的是,Google 已经知道如何进行全球性扩展,这样位于印度的用户在查看应用程序时会拥有和阿根廷用户相同的体验。
综上所述,您的确有必要牢记一些东西。Google 的基础设施支持 Java 技术,但是并不意味着所有内容;如果您回忆一下多年前 J2ME 问世的情景,那么 App Engine 的限制可能在本质上有些类似。也就是说,并非所有核心 Java 库和相关开源库都受支持。如前所述,Hibernate 就不受支持(主要是因为使用 App Engine 时,您无法拥有关系数据库)。我在使用某些内置了 base64 编码的开源库时还遇到了一些挑战(Google 要求您使用它的 URL Fetch 服务)。App Engine 是一个平台 — 您必须以它为方向进行开发,就目前而言,这是一个单向的过程。
结束语
面向对象编程的创始人之一 Alan Kay 曾经这样说道,“预测未来的最佳方式就是实现它”。我同意 Alan Kay 的这个说法。不管其他人如何预测 Java 技术的未来,我认为未来已经在您的面前。
正如您在本文中了解的那样,Google App Engine 正是面向未来的一个平台 — 假设您在其沙盒中试用。(注意,我只介绍了沙盒中的部分特性;App Engine 具有大量特性)。如果您希望获得更多的灵活性(就是说,希望拥有一个关系数据库并且必须使用 Hibernate),但是也希望借用其他人的可扩展基础设施,那么可以使用替代解决方案。Amazon 的 EC2 实际上就是位于按需使用的混合基础设施上的虚拟服务器。您将在下个月的 Java 开发 2.0 中了解它。
【编辑推荐】











