Dryad和DryadLINQ是微软硅谷研究院创建的研究项目,旨在提供一个分布式计算平台,近年来这个平台已经在微软内部得以广泛使用(如微软AdCenter中的数据分析)。在近日举行的微软2009年研究院教员峰会上,微软发布了Dryad/DryadLINQ的学术版,以及Trident项目(一个基于Dryad/DryadLINQ及微软其他一些技术的科研工作流平台)的CTP版本。
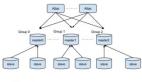
Dryad是微软分布式并行计算基础平台,使程序员可以利用数据中心的服务器集群对数据进行并行处理。Dryad程序员在操作数千台机器时,无需关心并行处理的细节。据Dryad论文描述:
Dryad被设计为伸缩于各种规模的计算平台:从单台多核计算机、到由几台计算机组成的小型集群,直至拥有数千台计算机的数据中心。Dryad执行引擎负责处理大型分布式、并行应用程序中会出现的各种难题:对计算机和它们的CPU进行调度,从通信或计算机的失败中恢复,以及数据在节点之间的传递等等。
DryadLINQ的目标是提供一种高级语言接口,使普通程序员可以轻易进行大规模的分布式计算,它结合了微软Dryad和LINQ两种关键技术。
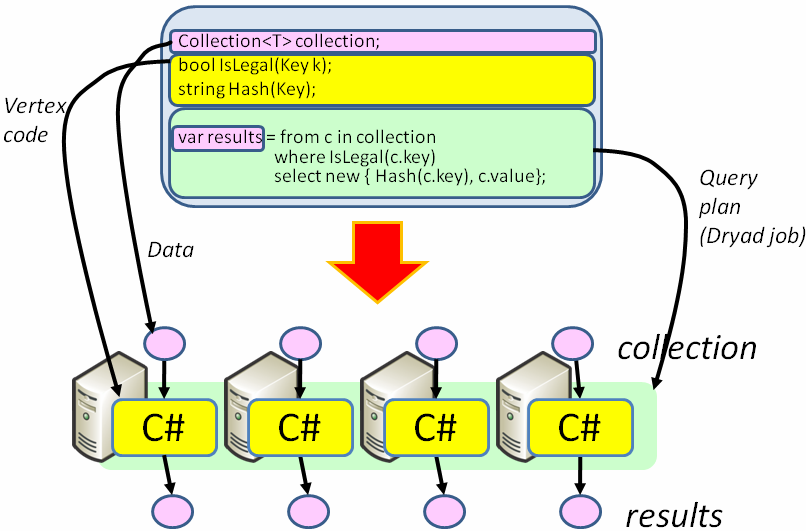
LINQ的理念为“代码即数据(treat code as data)”。如上图所示,DryadLINQ可以根据程序员给出的LINQ查询生成可以在Dryad引擎上执行的分布式运算规则,并负责任务的自动并行处理及数据传递时所需要的序列化等操作。此外,它还提供了一系列易于使用的高级特性,如强类型数据,Visual Studio集成调试,以及丰富的任务优化规则等等。以下是使用DryadLINQ获取一个柱状图所需数据的方式(引用自微软发布的示例代码):
- static IQueryable<Pair> Histogram(IQueryable<string> input, int k)
- {
- IQueryable<string> words = input.SelectMany(x => x.Split(' '));
- IQueryable<IGrouping<string, string>> groups = words.GroupBy(x => x);
- IQueryable<Pair> counts = groups.Select(x => new Pair(x.Key, x.Count()));
- IQueryable<Pair> ordered = counts.OrderByDescending(x => x.count);
- IQueryable<Pair> top = ordered.Take(k);
- return top;
- }
谈到大规模分布式计算技术,便不得不提起著名的Google MapReduce。据DryadLINQ论文(该论文获得OSDI 08最佳论文奖)所述,DryadLINQ与MapReduce的区别在于:
MapReduce同样提供了能够快速进行编程的简化抽象,但是,使用这种编程模型来实现一些最常见的操作,如数据库Join都要使用较为有技巧(tricky)的做法。还有,我们经常需要把MapReduce计算嵌入一种脚本语言来实现多次归并或排序操作。每个MapReduce阶段(stage)都是自治的(self-contained),因此无法跨越边界进行优化。此外,缺少类型系统来连接不同的MapReduce阶段,迫使程序员必须显式跟踪阶段间传递的对象,这导致软件长期维护以及组件的复用变得麻烦。
因此,出现了一些构建于MapReduce抽象上的DSL为程序员隐藏了一些复杂性,如Sawzall、Pig、以及其他一些未发表的系统,如Facebook的HIVE。这些DSL简单地结合了声明式与命令式的编程方式,并生成类似SQL存储过程的模型,这样便可以对跨越MapReduce阶段的边界进行一些整体的自动优化。然而,这些做法也带来了一些SQL的缺点,如过于简单的自定义类型系统,以及有限的交互式计算能力。它们提供的优化不如DryadLINQ来的有效,一部分原因在于Dryad比MapReduce执行平台的灵活性要高的多。
此外,微软发布的Trident项目是一个科学工作流控制台,为科学家们提供了一个灵活而强大的方式,可以对大规模的,变化纷繁的数据集进行分析。它提供了可视化工具来创建、管理和分享工作流,并且可以在Windows HPC Server 2008集群上执行这些工作流。Trident基于Dryad/DryadLINQ和WF开发,并提供了WPF和Siverlight两种版本的可视化界面。开发人员还可以扩展Trident,并与Word,SQL Server,Data Service等多种技术进行集成,使Trident的适用范围更为广泛。
【编辑推荐】