












Servlet源文件是以“.Java”结尾的文本文件。我们将讨论Servlet的编译过程并跟踪其中的中文变化。
用“Javac”编译Servlet源文件。Javac可以带“-encoding ”参数,意思是“用< Compile-charset >中指定的编码来解释Servlet源文件”。
源文件在编译时,用来解释所有字符,包括中文字符和ASCII字符。然后把字符常量转变成Unicode字符。最后,把Unicode转变成UTF。
在Servlet中,还有一个地方设置输出流的CharSet。通常在输出结果前,调用HttpServletResponse的setContent Type方法来达到与在JSP中设置一样的效果,称之为。
注意:文中一共提到了三个变量:、和。其中,JSP文件只与有关,而和只与Servlet有关。
看下例:
- import Javax.servlet.*;
- import Javax.servlet.http.*;
- Class testServlet extends HttpServlet
- {
- public void doGet(HttpServletRequest req,HttpServletResponse resp)
- throws ServletException,Java.io.IOException
- {
- resp.setContentType("text/html; charset=GB2312");
- Java.io.PrintWriter out=resp.getWriter();
- out.println("");
- out.println("#中文#");
- out.println("");
- }
- }
该文件也是用UltraEdit for Windows编写的,其中的“中文”两个字保存为字节流“D6 D0 CE C4”(GB2312编码)。
开始编译。Class文件中“中文”两字的十六进制码。在编译过程中,不起任何作用。只对Class文件的输出产生影响,可以说和一起,达到与JSP文件中的相同的效果,因为对编译过程和Class文件的输出都会产生影响。
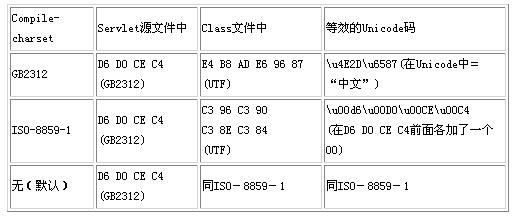
从Servlet源文件到Class的转变过程
注意:普通Java程序的编译过程与Servlet完全一样。
截止现在,从JSP或Servlet源文件到Class文件的过程中中文内容的蜕变历程是不是昭然若揭了?OK,接下来看看Class文件中的中文又是怎样被输出的呢?
Class:输出字符串
Class文件是Java程序的一种存储载体。当Class文件被虚拟机执行时,通过readUTF把Class文件中的内容读入内存中。字符串在内存中表示为Unicode编码。当要把内存中的内容输出到别的程序或是外围设备(如终端)上去时,问题就来了(为了简单起见,把“别的程序或外围设备”称之为“输出对象”)。
1.如果输出对象能处理Unicode字符,则一切都很简单,只要把Unicode字符直接传给输出对象即可。
2.事实是,大多数输出对象不能直接处理Unicode,它们只能处理ISO8859-1和GB2312等。在往输出对象输出字符串时,需要做一定的转换才行。
看看下面的例子,给定一个有四个字符的Unicode字符串“00D6 00D0 00CE 00C4”,如果输出到只能识别“ISO8859-1”的程序中去,则直接去掉前面的“00”即可得到目的字符串“D6 D0 CE C4”。假如把它们输出到GB2312的程序中去,得到的结果很可能是一大堆乱码。因为在GB2312中可能没有(也有可能有)字符与00D6等字符对应(如果对应不上,将得到0x3f,也就是问号,如果对应上了,由于00D6等字符太靠前,估计也是一些特殊符号,真正的汉字在Unicode中的编码从 4E00开始)。
同样的Unicode字符,输出到不同编码的对象中去时,结果是不同的。当然,这其中有一种是我们期望的结果。对于能处理中文的输出对象而言,自然希望输入的内容(也就是Java程序输出的内容)是基于GB2312编码有意义的中文字符串。
以上Servlet源文件的例子而论,“D6 D0 CE C4”应该是我们所想要的。当把“D6 D0 CE C4”输出到IE中时,用“简体中文”方式查看,就能看到清楚的“中文”两个字了。
【编辑推荐】










