表分区功能,相当于把一张表大数据无限极细化到多张表上,多个驱动上,但是访问时却还是一样的访问,因为 其实本身并未新建任何表,并且它还可以访问其他服务器以提高速度
好了,废话不谈了,下面的步骤 依次跟着来:
1.为数据库新建多个文件组,可分布于不同大磁盘上
- ALTER DATABASE [D]
- ADD FILEGROUP [GF1]
2.一个文件组可放置多个文件,下面,只为一个文件组分配一个文件
- ALTER DATABASE [D] ADD FILE ( NAME = N'GF1', FILENAME = N'E:\D\D1\DGF1.ndf' , SIZE = 5MB , FILEGROWTH = 10% )
- TO FILEGROUP [GF1]
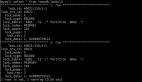
3.创建分区函数
- CREATE PARTITION FUNCTION [D_PARTITIONFUNC] (int)
- AS RANGE LEFT FOR VALUES (200000,400000,500000)
4.将分区函数绑定到分区架构上
- CREATE PARTITION SCHEME [D_PARTITION_SHEME]
- AS PARTITION [D_PARTITIONFUNC]
- TO ([PRIMARY],[GF1],[PRIMARY],[GF1])
注意primary表示主文件组,既是数据库建立大时候默认的
5.删除主键
- ALTER TABLE dbo.B DROP CONSTRAINT [PK_B]
上一步可以不做,不过我个人推荐,因为分区键(分区函数的参数)必须建立在主键上
6.开始对表分区
- ALTER TABLE dbo.B add CONSTRAINT [PK_B] PRIMARY KEY CLUSTERED (ID)
- ON [D_PARTITION_SHEME](ID)
OK,完成
B表中主键ID,好了
现在即使是几百G的数据也不会有问题了
【编辑推荐】