1、MySQL Replication复制进程
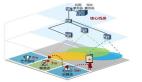
MySQL的复制(replication)是一个异步的复制,从一个MySQL instace(称之为Master)复制到另一个MySQL instance(称之Slave)。实现整个复制操作主要由三个进程完成的,其中两个进程在Slave(Sql进程和IO进程),另外一个进程在Master(IO进程)上。
要实施复制,首先必须打开Master端的binary log(bin-log)功能,否则无法实现。因为整个复制过程实际上就是Slave从Master端获取该日志然后再在自己身上完全顺序的执行日志中所记录的各种操作。
MySQL Replication复制的基本过程如下:
1)、Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
2)、Master接收到来自Slave的IO进程的请求后,通过负责复制的IO进程根据请求信息读取制定日志指定位置之后的日志信息,返回给Slave的IO进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置;
3)、Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的高速Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”;
4)、Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行。
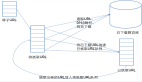
实际上在老版本的MySQL的复制实现在Slave端并不是两个进程完成的,而是由一个进程完成。但是后来发现这样做存在较大的风险和性能问题,主要如下:
首先,一个进程就使复制bin-log日志和解析日志并在自身执行的过程成为一个串行的过程,性能受到了一定的限制,异步复制的延迟也会比较长。
另外,Slave端从Master端获取bin-log过来之后,需要接着解析日志内容,然后在自身执行。在这个过程中,Master端可能又产生了大量变化并声称了大量的日志。如果在这个阶段Master端的存储出现了无法修复的错误,那么在这个阶段所产生的所有变更都将永远无法找回。如果在Slave端的压力比较大的时候,这个过程的时间可能会比较长。
所以,后面版本的MySQL为了解决这个风险并提高复制的性能,将Slave端的复制改为两个进程来完成。提出这个改进方案的人是Yahoo!的一位工程师“Jeremy Zawodny”。这样既解决了性能问题,又缩短了异步的延时时间,同时也减少了可能存在的数据丢失量。当然,即使是换成了现在这样两个线程处理以后,同样也还是存在slave数据延时以及数据丢失的可能性的,毕竟这个复制是异步的。只要数据的更改不是在一个事物中,这些问题都是会存在的。如果要完全避免这些问题,就只能用MySQL的cluster来解决了。不过MySQL的cluster是内存数据库的解决方案,需要将所有数据都load到内存中,这样就对内存的要求就非常大了,对于一般的应用来说可实施性不是太大。
2、MySQL Replication复制实现级别
MySQL Replication复制可以是基于一条语句(Statement level),也可以是基于一条记录(Row level),可以在MySQL的配置参数中设定这个复制级别,不同复制级别的设置会影响到Master端的bin-log记录成不同的形式。
Row Level:日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改。
优点:在row level模式下,bin-log中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了。所以row level的日志内容会非常清楚的记录下每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题。
缺点:row level下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比如有这样一条update语句:update product set owner_member_id = ‘b’ where owner_member_id = ‘a’,执行之后,日志中记录的不是这条update语句所对应额事件(MySQL以事件的形式来记录bin-log日志),而是这条语句所更新的每一条记录的变化情况,这样就记录成很多条记录被更新的很多个事件。自然,bin-log日志的量就会很大。尤其是当执行alter table之类的语句的时候,产生的日志量是惊人的。因为MySQL对于alter table之类的表结构变更语句的处理方式是整个表的每一条记录都需要变动,实际上就是重建了整个表。那么该表的每一条记录都会被记录到日志中。
Statement Level:每一条会修改数据的sql都会记录到 master的bin-log中。slave在复制的时候sql进程会解析成和原来master端执行过的相同的sql来再次执行。
优点:statement level下的优点首先就是解决了row level下的缺点,不需要记录每一行数据的变化,减少bin-log日志量,节约IO,提高性能。因为他只需要记录在Master上所执行的语句的细节,以及执行语句时候的上下文的信息。
缺点:由于他是记录的执行语句,所以,为了让这些语句在slave端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在slave端杯执行的时候能够得到和在master端执行时候相同的结果。另外就是,由于MySQL现在发展比较快,很多的新功能不断的加入,使MySQL得复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug也就越容易出现。在statement level下,目前已经发现的就有不少情况会造成MySQL的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现,比如:sleep()函数在有些版本中就不能真确复制,在存储过程中使用了last_insert_id()函数,可能会使slave和master上得到不一致的id等等。由于row level是基于每一行来记录的变化,所以不会出现类似的问题。
从官方文档中看到,之前的MySQL一直都只有基于statement的复制模式,直到5.1.5版本的MySQL才开始支持row level的复制。从5.0开始,MySQL的复制已经解决了大量老版本中出现的无法正确复制的问题。但是由于存储过程的出现,给MySQL Replication复制又带来了更大的新挑战。另外,看到官方文档说,从5.1.8版本开始,MySQL提供了除Statement Level和Row Level之外的第三种复制模式:Mixed,实际上就是前两种模式的结合。在Mixed模式下,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。新版本中的Statment level还是和以前一样,仅仅记录执行的语句。而新版本的MySQL中队row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
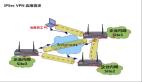
3、MySQL Replication复制常用架构
MySQL Replication复制环境90%以上都是一个Master带一个或者多个Slave的架构模式,主要用于读压力比较大的应用的数据库端廉价扩展解决方案。因为只要master和slave的压力不是太大(尤其是slave端压力)的话,异步复制的延时一般都很少很少。尤其是自slave端的复制方式改成两个进程处理之后,更是减小了slave端的延时。而带来的效益是,对于数据实时性要求不是特别的敏感度的应用,只需要通过廉价的pc server来扩展slave的数量,将读压力分散到多台slave的机器上面,即可解决数据库端的读压力瓶颈。这在很大程度上解决了目前很多中小型网站的数据库压力瓶颈问题,甚至有些大型网站也在使用类似方案解决数据库瓶颈。
一个Master带多个slave的架构实施非常简单,多个slave和单个slave的实施并没有太大区别。在Master端并不care有多少个slave连上了master端,只要有slave进程通过了连接认证,向他请求binlog信息,他就会按照连接上来的io进程的要求,读取自己的binlog信息,返回给slave的IO进程。对于slave的配置细节,在MySQL的官方文档上面已经说的很清楚了,甚至介绍了多种实现slave的配置方法。
MySQL不支持一个Slave instance从属于多个Master的架构。就是说,一个slave instance只能接受一个master的同步源,听说有patch可以改进这样的功能,但没有实践过。MySQL AB之所以不实现这样的功能,主要是考虑到冲突解决的问题。
MySQL也可以搭建成dual master模式,也就是说两个MySQL instance互为对方的Master,也同时为对方的Slave。不过一般这种架构也是只有一端提供服务,避免冲突问题。因为即使在两边执行的修改有先后顺序,由于复制的异步实现机制,同样会导致即使在晚做的修改也可能会被早做的修改所覆盖,就像如下情形:
时间点 MySQL A MySQL B
1 更新x表y记录为10
2 更新x表y记录为20
3 获取到A日志并应用,更新x表的y记录为10(不符合期望)
4 获取B日志更新x表y记录为20(符合期望)
这样,不仅在B库上面的数据不是用户所期望的结果,A和B两边的数据也出现了不一致的情况。除非能将写操作根据某种条件固定分开在A和B两端,保证不会交叉写入,才能够避免上面的问题。
【编辑推荐】