













SSAS为我们提供了九种数据挖掘算法,但是在应用中我们需要根据实际问题设计适当的算法,这个时候就需要扩展SSAS,使它能应用更多的算 法,SSAS有比较好的可扩展性,它提供了一个完整的机制来进行扩展,只要继承一些类并按适当的方法进行注册就可以在SSAS中使用自己的算法了。
下面我将通过实例分别用几篇文章来介绍一下如何开发SSAS算法插件。本文介绍的算法插件开发方法是基于托管代码的,是用C#开发的(算法插件也可以用C++开发,并且SQLSERVER2005的案例中附带C++版本的代码stub)。整个过程大至为六个步骤。在开始开发之前需要做一些准备工作,就是要去下载 一个用C++编写的COM组件,叫DMPluginWrapper(可以通过下载本文附带的附件获得),它作为SSAS与算法插件的中间层,用于处理 SSAS与算法插件之间的交互以及封装从SSAS到算法插件的参数和从算法插件到SSAS的处理结果。DMPluginWrapper、SSAS和算法插 件之间的关系可以由下图来描述。
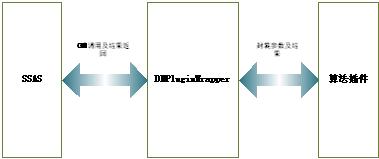
图表 1: DMPluginWrapper、SSAS和算法插件之间的关系
下面开始创建算法扩展的项目。
首先新建一个类库项目(名为AlgorithmPlugin)将刚才的DMPluginWrapper项目引用到新建的这个 AlgorithmPlugin类库项目中。你可以选择为这个类库项目进行程序集签名,这样就可以将其注册到GAC中。另外还要为 DMPluginWrapper添加后生成脚本将程序集注册到GAC,参考脚本如下(根据机器具体设置而定):
"C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727\RegAsm.exe" $(TargetPath) |
如果***行脚本不能正确运行的话,算法插件是不能被SQLSERVER分析服务器识别的。另外两行脚本就是将算法程序集注册到GAC。
接下来的几个步骤主要是继承一些基类的工作,包括AlgorithmMetadataBase类、AlgorithmBase类和 ICaseProcessor接口和AlgorithmNavigationBase类。首先在AlgorithmPlugin中新建一个类文件并命名为 Metadata,为这个类添加ComVisible、MiningAlgorithmClass(typeof(Algorithm))和Guid属性 (Algorithm是下面要创建的算法类),并为Guid属性指定一个GUID编码。这个类要继承于AlgorithmMetadataBase类。现 在要做的事情就是覆盖基类的方法。下面是所有需要覆盖的方法(对于较简单的实现写在表格中):
方法名实现(参考)备注
GetServiceName |
用于指定算法适用的规模,这个值不会被服务器使用而是显示在模式行集中,为用户提供算法的一些相关信息。
GetTrainingComplexity
return MiningTrainingComplexity.Low
用于指定算法训练适用的复杂度,这个值不会被服务器使用而是显示在模式行集中,为用户提供算法的一些相关信息。
GetPredictionComplexity
return MiningPredictionComplexity.Low
用于指定预测复杂度,这个值不会被服务器使用而是显示在模式行集中,为用户提供算法的一些相关信息。
GetSupportsDMDimensions
retrun false;
GetSupportsDrillThrough
return false;
指定这个算法是否支持钻透功能。
GetDrillThroughMustIncludeChildren
return false;
GetCaseIdModeled
return false;
GetMarginalRequirements
return MarginalRequirements.AllStats
GetParametersCollection
return null;
算法参数,因为本文中的例子没有参数,所以这里返回空。
GetSupInputContentTypes
MiningColumnContent[] arInputContentTypes = new MiningColumnContent[]{
MiningColumnContent.Discrete,
MiningColumnContent.Continuous,
MiningColumnContent.Discretized,
MiningColumnContent.NestedTable,
MiningColumnContent.Key
};
return arInputContentTypes;
指定算法所支持的输入属性的数据类型,如连续型、离散型等。
GetSupPredictContentTypes
MiningColumnContent[] arPredictContentTypes = new MiningColumnContent[]{
MiningColumnContent.Discrete,
MiningColumnContent.Continuous,
MiningColumnContent.Discretized,
MiningColumnContent.NestedTable,
MiningColumnContent.Key
};
return arPredictContentTypes;
与上一个方法类似,这里是指定预测属性所支持的数据类型。
GetSupportedStandardFunctions
SupportedFunction[] arFuncs= new SupportedFunction[] {
SupportedFunction.PredictSupport,
SupportedFunction.PredictHistogram,
SupportedFunction.PredictProbability,
SupportedFunction.PredictAdjustedProbability,
SupportedFunction.PredictAssociation,
SupportedFunction.PredictStdDev,
SupportedFunction.PredictVariance,
SupportedFunction.RangeMax,
SupportedFunction.RangeMid,
SupportedFunction.RangeMin,
SupportedFunction.DAdjustedProbability,
SupportedFunction.DProbability,
SupportedFunction.DStdDev,
SupportedFunction.DSupport,
SupportedFunction.DVariance,
// content-related functions
SupportedFunction.IsDescendent,
SupportedFunction.PredictNodeId,
SupportedFunction.IsInNode,
SupportedFunction.DNodeId,
};
return arFuncs;
指定DMX所支持的函数。
CreateAlgorithm
return new Algorithm();
返回算法实例,Algorithm是接下来要创建的类。
现在创建第二个类,命名为Algorithm.cs。这个类要继承于AlgorithmBase并实现ICaseProcesses接口,这是实现算法最重要的一个类,主要的算法处理都在这个类中进行。这个类要有一个成员变量TaskProgressNotification trainingProgress。这个类包含了算法主要的处理逻辑。下面是要实现的方法:
方法名://处理样本
InsertCases
参考实现:
Code
//遍历所有的样本并且每处理100个样本更新一次处理进度。
trainingProgress = this.Model.CreateTaskNotification();// 设置当前的处理进度为0
trainingProgress.Current = 0;// 取得总的样本数量。
trainingProgress.Total =
(int)this.MarginalStats.GetTotalCasesCount();// 为跟踪提示信息设置格式字符串
trainingProgress.Format = "Processing cases: {0} out of {1}";// 开始处理
trainingProgress.Start();
bool success = false;
try
{
caseSet.StartCases(this);
success = true;
}
finally
{
trainingProgress.End(success);
}
方法名:ProcessCase
参考实现:
Code
// 检查并确认处理过程没有被中断。
this.Context.CheckCancelled();// 更新当前的进度值
trainingProgress.Current++;if (caseId % 100 == 0)
{
trainingProgress.Progress();
}
//TODO: 在这里进行实际的模型训练处理逻辑
方法名:SaveContent参考实现:
Code
//创建一个自定义的标签内容用于保存处理结果(其结构类似XML),MyPersistenceTag是自定义的枚举类型writer.OpenScope((PersistItemTag)MyPersistenceTag.ShellAlgorithmContent);
writer.SetValue(System.DateTime.Now);
writer.SetAttribute((PersistItemTag)MyPersistenceTag.NumberOfCases,
this.MarginalStats.GetTotalCasesCount());
writer.CloseScope();
方法名:LoadContent
参考实现:
Code
//打开自定义的标签(与SaveContent方法相对应)
reader.OpenScope((PersistItemTag)MyPersistenceTag.ShellAlgorithmContent);//读取处理时间
System.DateTime processingTime;
reader.GetValue(out processingTime);// 取得处理的样本数量
uint numberCases = 0;reader.GetAttribute((PersistItemTag)MyPersistenceTag.NumberOfCases, out numberCases);
reader.CloseScope();
方法名:Predict
参考实现:
Code
AttributeGroup targetAttributes = predictionResult.OutputAttributes;
targetAttributes.Reset();
uint nAtt = AttributeSet.Unspecified;//对于每一个目标属性,从训练集中复制预测结果
while (targetAttributes.Next(out nAtt))
{
//创建一个AttributeStatistics对象用于保存对当前目标属性的预测结果
AttributeStatistics result = new AttributeStatistics();//设置预测结果中的目标属性,即当前的预测结果针对于哪个输入属性
result.Attribute = nAtt;// 取得当前属性的概率统计值,也即通过模型训练得到的边缘统计概率。
AttributeStatistics trainingStats = this.MarginalStats.GetAttributeStats(nAtt);//复制其余的数据到结果对象
result.AdjustedProbability = trainingStats.AdjustedProbability;
result.Max = trainingStats.Max;
result.Min = trainingStats.Min;
result.Probability = trainingStats.Probability;
result.Support = trainingStats.Support;//复制状态统计到结果对象中
if (predictionResult.IncludeStatistics)
{
for ( int nIndex = 0; nIndex < trainingStats.StateStatistics.Count; nIndex++)
{
bool bAddThisState = true;// 如果是丢失值状态,那么只有当需要的时候才将其包含在结果之中。
if (trainingStats.StateStatistics[0].Value.IsMissing)
{
bAddThisState = predictionResult.IncludeMissingState;
}if (bAddThisState)
{
result.StateStatistics.Add(
trainingStats.StateStatistics[(uint)nIndex]);
}
}
}//如果预测需要内容结点,就要为内容结点设置一个唯一的编号
if (predictionResult.IncludeNodeId)
{
result.NodeId = "000";
}
predictionResult.AddPrediction(result);
方法名:GetNavigator参考实现:
Code
//AlgorithmNavigator是下面要创建的类
return new AlgorithmNavigator(this, forDMDimensionContent);
接下来要实现的是AlgorithmNavigator类,这个类要继承于 AlgorithmNavigationBase。这个类主要用于显示算法处理结果中所有结点的信息。在这个类中有三个成员变量:Algorithm类型 的algorithm、bool类型的forDMDimension和int类型的currentNode。下面是这个类要实现的方法:
方法名(构造方法):AlgorithmNavigator参考实现:
Code
this.algorithm = currentAlgorithm;
this.forDMDimension = dmDimension;
this.currentNode = 0;
方法名
实现
备注
MoveToNextTree
return false;
GetCurrentNodeId
return currentNode;
ValidateNodeId
return (nodeId == 0);
LocateNode
if (!ValidateNodeId(nodeId))return false;
currentNode = nodeId;
return true;
GetNodeIdFromUniqueName
int nNode = Convert.ToInt32(nodeUniqueName);return nNode;
GetUniqueNameFromNodeId
return nodeId.ToString("D3");
按三位数字的格式输出结点编号
GetParentCount
return 0;
GetParentNodeId
return 0;
GetChildrenCount
return 0
GetChildNodeId
return -1;
GetNodeType
return NodeType.Model;
GetNodeUniqueName
return GetUniqueNameFromNodeId(currentNode);
GetNodeAttributes
return null;
方法名:
//此方法返回了描述结点的数值特征
GetDoubleNodeProperty
参考实现:
Code
double dRet = 0;
double dTotalSupport = lgorithm.MarginalStats.GetTotalCasesCount();
double dNodeSupport = 0.0;
dNodeSupport = dTotalSupport;
switch (property)
{
//结点的支持度
case NodeProperty.Support:
dRet = dNodeSupport;
break;
case NodeProperty.Score:
dRet = 0;
break;
//结点概率
case NodeProperty.Probability:
dRet = dNodeSupport / dTotalSupport;
break;
//结点的边缘概率
case NodeProperty.MarginalProbability:
dRet = dNodeSupport / dTotalSupport;
break;
}
return dRet;
方法名://取得结点的字符串表示
GetStringNodeProperty
参考实现:
Code
string strRet = "";
switch (property)
{
case NodeProperty.Caption:
{
strRet = algorithm.Model.FindNodeCaption(GetNodeUniqueName());
if (strRet.Length == 0)
{
strRet = "All";
}
}
break;
case NodeProperty.ConditionXml:
strRet = "";
break;
case NodeProperty.Description:
strRet = "All Cases";
break;
case NodeProperty.ModelColumnName:
strRet = "";
break;
case NodeProperty.RuleXml:
strRet = "";
break;
case NodeProperty.ShortCaption:
strRet = "All";
break;
}
return strRet;
方法名:
//取得结点的分布
GetNodeDistribution
参考实现:
Code
int attStats = (int)algorithm.AttributeSet.GetAttributeCount();
AttributeStatistics[] marginalStats = new AttributeStatistics[attStats];
for (uint nIndex = 0; nIndex < attStats; nIndex++)
{
marginalStats[nIndex] = algorithm.MarginalStats.GetAttributeStats(nIndex);
}
return marginalStats;
现在我们已经实现了完所有需要要实现的类,***要做的就是将算法插件部署到分析服务器。在完成代码后,需要将程序集注册到GAC以便分析服务器 可以从中加载插件。下面的代码就是将DMPluginWrapper加载到GAC的脚本,如果在本文的开头正确地在Visual Studio中设置了后生成(Post-Building)脚本的话可以跳过下面的脚本代码,因为它们是相同的功能:
//将DMPluginWrapper.dll注册到GAC中 |
注意以上的路径一定要与自己机器的设置匹配。成功运行上面的脚本后算法插件就被注册到计算机之中,但要在分析服务器中使用这个算法还有一项工 作,就是把在分析服务器中注册这个算法。在分析服务器中注册算法有两种方式,一种是通过发送XMLA代码到分析服务器来注册;另一种是通过修改 SQLSERVER的配置文件来注册算法插件。下面先说***种:
通过XMLA方式注册算法插件——
| <!--Template for registering a plug-in algorithm Replace MyPluginAlgorithm with the ServiceName of your algorithm Replace 00000000-0000-0000-0000-000000000000 with the Guid of your Algorithm After deploying, you will need to restart the server to load the plug-in --><ALTER AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="<A href="http://schemas.microsoft.com/analysisservices/2003/engine"> http://schemas.microsoft.com/analysisservices/2003/engine</A>"><OBJECT> <ObjectDefinition> <BR><Server xmlns:xsd="<A href="http://www.w3.org/2001/XMLSchema">http://www.w3.org/2001/XMLSchema</A>" xmlns:xsi="<A href="http://www.w3.org/2001/XMLSchema-instance"> http://www.w3.org/2001/XMLSchema-instance</A>"> <Name>.</Name> <ServerProperties> <ServerProperty> <!-- 用自己的算法名称替换 --> <Name>MyFirstAlgorithmPlugin</Name> <!-- 是否启用算法 --> <Value>true</Value> </ServerProperty> <ServerProperty> <!-- 用自己的算法名称替换 --> <BR><Name>MyFirstAlgorithmPlugin</Name> <!--算法的GUID(在算法类中指定的GUID) --><Value>00000000-0000-0000-0000-000000000000</Value> </ServerProperty> </ServerProperties></Server> </ObjectDefinition> </Alter> |
通过修改SQLSERVER的配置文件注册算法——
找到SQLSERVER安装目录下的MSSQL.2\OLAP\Config\msmdsrv.ini文件。这个是一个XML格式的文档。文档内容类似于下面的代码:
<ConfigurationSettings> |
在以上的配置信息中算法名称是来自于Metadata类的GetServiceName这个方法,即在配置中设置的算法名称要与这个方法的返回值相同。到这里一个基本的算法插件程序就完成了,重启分析服务器后就可以在建立挖掘模型的窗口中看到新的算法出现在算法下拉列表中了。
从建立算法插件的整个过程来看,除开前后的准备工作和部署主要就是对三个类的重写,而其中最主要的类就是算法类的重写,其它两个类的主要作用是为算法提供元数据信息及结果的描述。在算法类中要实现挖掘模型的样本训练以及预测,这是算法最关键的地方,重写算法类中的ProcessCase方法和Predict方法是算法插件的核心。在了解如何扩展算法后要做的工作就是设计新的算法或将已经完成的算法集成到插件中。
【编辑推荐】










