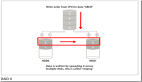
大部分用户都会担心,万一硬盘发生故障,数据丢失咱们办呢?其实现在不少用户由于硬盘容量等方面的限制,都会在主机上挂有不止一块的硬盘。此时若把这些硬盘组成一个磁盘阵列,那么用户就可以高枕无忧了。磁盘阵列可以将多个硬盘组成一个虚拟的硬盘。在操作上,用户会觉得跟使用单一硬盘没有什么不同。但是在实际存储数据过程中,磁盘阵列是将数据分别保存在不同的硬盘上,以提高数据的安全性。笔者今天将跟大家说说如何在Linux环境下玩转磁盘阵列。
一、使用磁盘阵列可以带来哪些好处?
在具体如何配置磁盘阵列之前,笔者要先给大家介绍一下利用磁盘阵列的好处。先给大家一点动力,让大家能够继续看下面的内容。
第一个好处是磁盘阵列可以提高数据存取的效率。硬盘其实就好像是一个盒子,其内部空间很大,但是出入的口子很小。当要把大量数据保存在这个盒子的时候,只有通过这个小小的盒子来保存数据。其存取的效率明显不是很高。但是,如果采用磁盘阵列的话,当系统向硬盘中写入数据的时候,会先把大块的数据分割成多个小区快,并同时写到不同的硬盘中。这就好像在一个盒子中开了多个出入孔,同时往这个孔中加入数据一样,可以提高硬盘的写入速度。同理,在读取的时候,也可以同时从不同的硬盘中读取,提高数据读取的速度。所以磁盘阵列可以提高数据的存储效率。为此,在一些服务器上部署磁盘阵列,可以提高服务器的应用性能。
第二个好处是可以整合多块硬盘。多数的Linux系统管理员也许都遇到过这种问题。一块硬盘用着用着,突然空间不够了。此时该如何处理呢?其实,管理员不需要更换硬盘。而是可以把多个小容量的硬盘整合起来,组合成一个容量比较大的虚拟硬盘。因为磁盘阵列操作起来,就好像跟一块硬盘一样,所以不会给用户的工作带来不利的影响。所以把多块闲置的硬盘利用磁盘阵列组合成一块虚拟硬盘,是解决磁盘容量不足的一个不错的方法。
第三个好处是可以提供比较高的安全性。当硬盘中的数据存储发生错误时,磁盘阵列技术能够利用现有的信息对损坏的数据进行自动修复。磁盘阵列会产生一个校验码。这个校验码会存放在不同的磁盘上。当某块磁盘突然出现损坏时,磁盘阵列技术就可以利用这个校验码来恢复损坏磁盘的数据。故磁盘阵列技术也经常被用在Linux服务器,以提高服务器数据的安全性。
二、Linux磁盘阵列与其它操作系统的差异。
从磁盘阵列的概念中,我们知道磁盘阵列是由一个个不同的硬盘组合而成的一个虚拟硬盘。其他操作系统,如微软操作系统,若要采用磁盘阵列的话,也有这方面的限制。但是,Linux与其他操作系统不同。它可以在同一块硬盘中实现磁盘阵列。也就是说,Linux操作系统不是以硬盘为单位来组成磁盘阵列的,而是以分区为单位。既可以通过把一个硬盘分割成不同的分区,然后再把它们组合成一个磁盘阵列。
不过在同一块硬盘上分割成多块分区,并重新组合成一个磁盘阵列的话,就不能够享受磁盘阵列所带来的好处。如上面所讲的提高硬盘数据存取效率、提高数据安全性等等,都将不在有。也就是说,其已经失去了将数据存放在不同磁盘、以降低数据损坏风险、提高数据存储效率的目的。磁盘阵列的使用价值将无法体现。
故系统管理员之所以把一块硬盘分割成不同的分区,并实现磁盘阵列,主要是出于实验、学习的目的。在实际部署中,笔者建议企业还是采用至少三块硬盘来实现磁盘阵列,让磁盘阵列真真发挥其应有的效益。
三、Linux系统下如何设置磁盘阵列?
在Linux系统中,磁盘阵列主要通过/etc/raidtab配置文件来控制的。若系统管理员需要实现磁盘阵列的话,就需要手工创建这个配置文件。或者从其他地方复制这个文件,并进行相应的修改。默认情况下,在Linux系统中不会有这个文件。下面笔者就对这个文件中的主要参数进行讲解,帮助大家建立一个正确的磁盘阵列配置文件。
参数一:raid-level 指定磁盘阵列的类型。
磁盘阵列到目前为止,有不下于十种的类型。而Linux系统则只支持其中的不种类型。系统管理员需要了解这五种磁盘阵列类型的特点,并根据企业的实际应用场景选择合适的磁盘类型。笔者平时比较喜欢采用Linear或者RAID-5这两种磁盘阵列类型。为此就给大家分析一下这两个磁盘类型的特点。
Linear磁盘阵列模式比较简单,它只是起到一个磁盘的整和作用。如果采用这种磁盘阵列模式,Linux系统会先将数据存放在第一块硬盘中。只有当这个硬盘空间已经使用完了,操作系统才会将数据存储到第二块硬盘中。以此类推。在这种模式下,由于没有把数据分块同时存入到多个硬盘中,所以不能够提高数据存取效率。同时,也不存在校验码,故也没有数据自我修复的功能。也就是说,这种模式的磁盘阵列,只起到了把小容量的硬盘整和中一块大硬盘的作用。所以这种模式实际应用的不多。但是因为其配置简单,所以是用来理解磁盘阵列这种技术的好渠道。
RAID-5磁盘阵列模式是现在主流的磁盘阵列模式。在这种模式下,Linux操作系统会将数据切割成固定大小的小区块,并同时分别保存到不同的硬盘中。而且这种磁盘阵列模式,会产生校验码,并且把校验码存放在不同的硬盘中。由于其并没有保留固定的一块硬盘来存放同为校验码,所以当任何一块硬盘损坏时,损坏的数据都可以被修复。若采用这种模式,可以提高数据的存储效率、增强数据的安全性、把不同硬盘整和成一块虚拟硬盘。而且,其没有把同位校验码存放在同一块硬盘中,所以不会造成整体系统性能的瓶颈。笔者现在企业中的服务器,就是采用了这种磁盘阵列模式。
#p#
参数二:chunk-size 指定分块的大小。
采用磁盘阵列后,数据会被分割成许多小块,然后写入到硬盘中。那么这个块的大小是多少呢?在磁盘阵列配置文件中,需要指定每个写入区块的大小。其最小单位是2KB。用户指定的区块大小,必须都是2的整数次方。如可以设置为4、8、16等等。不过这个参数配置对于Liner模式下没有实际意义。因为在Liner模式下实际上不会对数据进行分块。因为其先把数据存储在第一块硬盘上。当第一块硬盘满后在存储在第二块上,以此类推。故不会对数据进行分块。所以这个参数对Liner这种磁盘阵列模式不起作用。
参数三:persistent-superblock:设置是否要写入超级块。
在微软的操作系统下部署磁盘阵列的话,就不需要设置这个内容。但是在Linux下,必须对此进行设置。因为Linux系统采用的是Ext2/3文件系统。对于这个文件系统来说,硬盘分区首先被划分为一个个Block。同一个ext2文件系统上的每个block大小都是一样的。但是对于不同的ext2文件系统,block的大小可以有区别。典型的block大小是1024 bytes或者4096 bytes。这个大小在创建ext2文件系统的时候被决定,它可以由系统管理员指定,也可以由文件系统的创建程序根据硬盘分区的大小,自动选择一个较合理的值。一个硬盘分区上的block计数是从0开始的,并且这个计数对于这个硬盘分区来说是全局性质的。
Superblock有一个比较时髦的中文名称,叫做超级块。超级块是硬盘分区开头(开头的第一个byte是byte 0)从 byte 1024开始往后的一部分数据。由于 block size最小是 1024 bytes,所以super block可能是在block 1中(可能此时block 的大小正好是 1024 bytes),也可能是在block 0中(可能此时block 的大小超过 1024 bytes)。超级块中的数据其实就是文件卷的控制信息部分,也可以说它是卷资源表,有关文件卷的大部分信息都保存在这里。所以这个超级块中的信息就好像是FAT32文件系统下的分区格式,非常的重要。
这个参数就是用来控制是否需要写入硬盘的这个块。如果要写入的话,就设置为1;不写入的话,就设置为0。
【编辑推荐】