













尽管Python 很快在开发人员之中普及,但长久以来 Oracle 数据库一直是最出色的企业级数据库。采用有效的方式将这两者结合在一起是比较令人感兴趣的主题,但这实际上是真正的挑战,因为二者都要付出很多。
尽管受到警告,但本文并不会对最杰出的 Python 和 Oracle 数据库特性进行概述,而是提供一系列独立的示例。本文借助一个示例让您了解如何采用互补的方法尝试将这两种技术结合使用。尤其是,本文将指导您利用 PL/SQL 存储过程(在 Python 脚本中编排其调用)创建 Oracle 支持的 Python 应用程序,该应用程序在 Python 和数据库中实施业务逻辑。
正如您将在本文中学习到的,即使是轻型的 Oracle 数据库 10g 快捷版 (XE) 也可以得到有效利用,作为数据驱动的 Web 应用程序的数据库后端,其前端层使用 Python 构建。特别是,Oracle 数据库 XE 支持 Oracle XML DB,这是构建 Web 应用程序时通常需要的一组 Oracle 数据库 XML 技术。
示例应用程序
在用户使用您的应用程序时收集有关用户执行操作的信息成为一种比较流行的接收用户反馈的机制。通常,相对于让用户明确表达偏好的任何调查来说,并入在线应用程序中的点击跟踪工具可以为您提供有关用户偏好的大量信息。
举一个简单的例子,假设您想从“OTN — 新文章 RSS”页面中选取三个最新的 Oracle 技术网 (OTN) 文章标题,并将这些链接放到您的站点上。然后,您希望收集有关用户在您的站点上跟随这些链接中的每个链接的次数的信息。这就是我们的示例将要做的。现在,让我们试着弄清如何实现所有这些功能。首先,必须决定如何在应用程序层之间分发业务逻辑。实际上,决定如何在应用程序层之间分发业务逻辑可能是规划数据库驱动的应用程序最具挑战性的部分。尽管执行业务逻辑通常有多种方法,但是您的工作是找到最有效的方法。作为一般的经验,当规划数据库驱动的应用程序时,您应该认真考虑数据库中关键数据处理逻辑的实现。这种方法可以帮助您削减与在 Web 服务器和数据库之间发送数据相关的网络开销,并且可以减轻 Web 服务器的负担。
将所有这些理论应用到我们的示例上,例如,将获得插入到数据库中的文章详细信息的负担放到在数据库中创建的存储过程上,这样 Web 服务器不必再处理与维护数据完整性有关的任务。这在实践中的意义是您不必编写特定 Python 代码,这些代码负责跟踪数据库中是否存在与其链接被点击的文章有关的记录,如果不存在,则插入该记录,然后从“OTN — 新文章 RSS”页面中获取所需的所有详细信息。通过让数据库自己跟踪此类事情,您可以获得具有更高可扩展性且更不易出错的解决方案。在本例中,Python 代码将只负责从 RSS 页面获取文章链接,并在用户单击某个文章链接时向数据库发送一条消息。
图 1 给出了示例组件如何彼此交互以及如何与外部源交互的图形描述。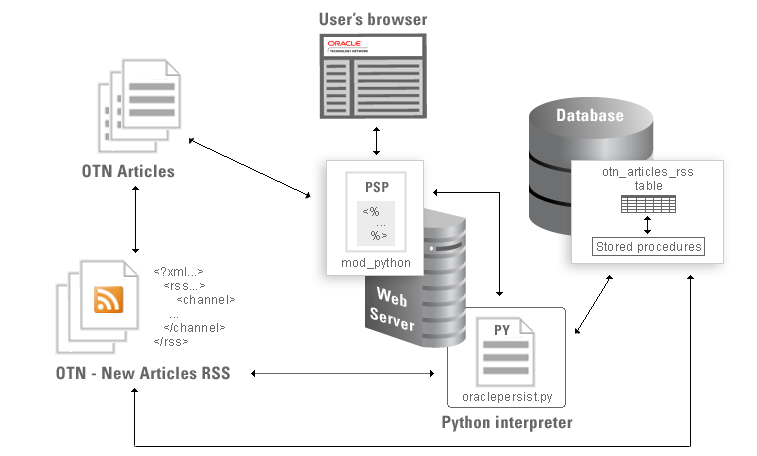
图 1:示例应用程序工作原理的高级视图。
本文的其余部分介绍如何实现此示例应用程序。有关如何设置和启动此示例的简要描述,可以参考示例代码根目录下的 readme.txt 文件。
准备工作环境
要构建此处讨论的示例,您需要安装以下软件组件(参见 Downloads portlet)并使其在您的系统中正常工作:
Apache HTTP Server 2.x
Oracle 数据库 10g 快捷版
Python 2.5 或更高版本
mod_python 模块
cx_Oracle 模块
有关如何安装上述组件的详细说明,可以参考另一篇 OTN 文章“为 Python Server Pages 和 Oracle 构建快速 Web 开发环境”(作者:Przemyslaw Piotrowski)。
#p#
设计基础数据库
一般来说,最好从设计基础数据库开始。假设您创建了一个用户模式并授予其创建和操作模式对象所需的所有权限,那么第一步就是创建基础表。在这种特殊情况下,您将需要一个唯一的名为 otn_articles_rss 的表,创建该表的方式如下:
CREATE TABLE otn_articles_rss ( |
下一步是设计一个将在 Python 代码中调用的名为 count_clicks 的存储过程,它更新 otn_articles_rss 表中的数据。继续 count_clicks 过程之前,您必须先回答以下问题:当 count_clicks 尝试更新尚未插入到 otn_articles_rss 表中的文章记录的 clicks 字段时,会发生什么情况呢?假设一个新项目刚刚添加到 RSS 页面,然后指向该项目的链接出现在您的站点上。当有人单击该链接时,系统将从负责处理指向 OTN 文章的链接上执行的单击次数的 Python 代码中调用 count_clicks PL/SQL 过程。显然,处理第一次单击时,在 count_clicks 过程中发出的 UPDATE 语句将失败,因为现在还没有要更新的行。
要适应此类情况,您可以在 count_clicks 过程中实现一个 IF 块,如果由于 UPDATE 找不到指定的记录而将 SQL%NOTFOUND 属性设置为 TRUE 时,该块会发挥作用。在该 IF 块中,只要指定了 guid 和单击次数,您就可以先将一个新行插入到 otn_articles_rss 表中。之后,您应该提交这些更改,以便这些更改立即可用于其他用户会话,这些会话可能也需要更新新插入的文章记录的 clicks 字段。最后,您应该更新该记录,设置其 title、pubDate 和 link 字段。该逻辑可以作为一个单独的过程(比如 add_article_details)来实现,该过程的创建方式如下:
CREATE OR REPLACE PROCEDURE add_article_details (gid VARCHAR2, clks NUMBER) AS 'http://feeds.delicious.com/v2/rss/OracleTechnologyNetwork/otntecharticle').getXML(), |
正如您所见,该过程接受两个参数。gid 是其链接受到单击的文章的 guid。clks 是文章查看总次数的增量。在该过程主体中,您获得 RSS 文档的所需部分作为 XMLType 实例,然后提取信息,之后该信息将立即用于填充 otn_articles_rss 中与正在处理的 RSS 项目关联的记录。
借助 add_article_details,您可以继续下一环节,按照如下方式创建 count_clicks 过程:
CREATE OR REPLACE PROCEDURE count_clicks (gid VARCHAR2, clks NUMBER) AS BEGIN |
事务考虑事项
在上面清单中所示的 count_clicks 存储过程中,注意 COMMIT 的使用要紧跟在 INSERT 语句之后。最重要的是,之后要调用 add_article_details,其执行时间可能较长。通过在这个阶段提交,新插入的文章记录立即用于其他可能的更新,否则要等待 add_article_details 完成。
考虑以下示例。假设 RSS 页面刚刚更新并且一个全新的文章链接变为可用。接下来,两个不同的用户加载您的页面并几乎同时单击这个新链接。因此,将进行两个对 count_clicks 的同时调用。在本例中,首先发生的调用将一条新记录插入到 otn_articles_rss 表中,然后它将调用 add_article_details。虽然正在执行 add_article_details,但对 count_clicks 的另一个调用可以成功执行更新操作,增加总单击次数。但是,如果此处忽略了 COMMIT,那么第二个调用将找不到用于更新的行,因此尝试执行另一个插入。事实上,这将导致不可预测的结果。它将导致独特的违反约束的错误,并且会丢失将第二次 count_clicks 调用进行的更新。
此处最令人感兴趣的部分是在 count_clicks 过程主体结尾处执行另一个 COMMIT 操作。正如您所猜测的,需要在这个阶段提交以便从更新的记录中去除锁定,从而使该记录立即可用于其他会话执行的更新。有些人可能会说这个方法降低了灵活性,使客户端无法根据自己的判断提交或回滚事务。但是,在这种特殊的情况下,这并不是一个大问题,因为无论如何从调用 count_clicks 开始的事务都应该立即提交。这是因为当用户单击某个文章链接以离开您的页面时,始终会调用 count_clicks。
构建前端层
既然已经创建了存储过程并且准备好在应用程序中使用,那么您必须弄清如何从前端层编排在数据库中实现的所有这些应用程序逻辑片段所执行的整个操作流。这就是 Python 派上用场的地方了。
我们先来看一个简单的实现。为了开始,您必须编写一些 Python 代码,这些代码将负责从“OTN — 新文章 RSS”页面获取数据。然后,您将需要开发一些代码,这些代码将处理在 Web 页面中的 OTN 文章链接上执行的单击。最后,您将需要构建该 Web 页面本身。为此,您可能会使用 Python 的一种服务器端技术,比如 Python Server Pages (PSP),这使得将 Python 代码嵌入到 HTML 中成为可能。
为了编写 Python 代码,您可以使用您喜欢的文本编辑器,如 vi 或记事本。创建一个名为 oraclepersist.py 的文件,然后在其中插入以下代码,将该文件保存到 Python 解释器可以找到的位置:
import cx_Oracle import urllib2 latest.append(dict(zip(inxs,[item.getElementsByTagName(inx)[0].firstChild.data for inx in inxs]))) |
正如您所猜测的,上面所示的 getRSS 函数将用来从 RSS 页面获取数据,并将该数据作为一个 DOM 对象返回。getLatestItems 专门用来处理该 DOM 文档,将该文档转换为 Python dictionary 对象。
在 getLatestItems 函数中,注意列表内涵(一个新的 Python 语言特性)的使用,它提供了一种出色的方法,可显著简化数据处理任务的编码。
下一步涉及一些代码的创建,这些代码将处理在指向 OTN 文章的链接上执行的单击,这些链接是从“OTN — 新文章 RSS”页面中获取并放置到 Web 页面上的。为此,您可以开发另一个自定义 Python 函数(比如说 processClick),每次用户单击您 Web 页面上的 OTN 文章链接时都会调用该函数。要实现 processClick,将以下代码添加到 oraclepersist.py:
def processClick(guid, clks = 1): db = cx_Oracle.connect('usr', 'pswd', '127.0.0.1/XE') |
以上代码提供了实际运行的 cx_Oracle 的一个简单示例。它首先连接到基础数据库。然后,它获得一个 Cursor 对象,之后使用该对象的 execute 方法调用在之前的“设计基础数据库”部分讨论的 count_clicks 存储过程。
现在,您可以继续下一环节,构建 Web 页面。由于这是仅用于演示的应用程序,因此该页面可能非常简单,只包含从 RSS 页面获得的链接。在 APACHE_HOME/htdocs 目录中,创建一个名为 clicktrack.psp 的文件,然后在其中插入以下代码:
﹤html﹥ |
正如您所见,以上文档包含几个嵌入的 Python 代码块。在第一个块中,您从之前按照该部分所述创建的 oraclepersist 模块调用函数,获得列表的一个实例,该列表的项目代表三篇最新的 OTN 文章。然后,在 for 循环中循环该列表,为该列表中存在的每个文章项目生成一个链接。令人感兴趣的是,尽管这些链接中的每个链接都引用相应的 OTN 文章地址,但是链接的 onclick 处理程序将动态修改链接到 dispatcher.psp 页面的目标,该目标需要在 APACHE_HOME/htdocs 目录中创建。将两个参数(即 guid 和 url)附加到每个动态生成的链接,向 dispatcher.psp 提供有关正在加载的文章的信息。
以下是 dispatcher.psp 的代码:
﹤html﹥ |
在以上代码中,借助 FieldStorage 类的帮助访问了附加到 URL 的参数,该类来自 mod_python 网页上提供的 Mod_python 手册中描述的 util 模块。然后,从我们的 oraclepersist 自定义模块中调用 processClick 函数,将从 URL 中提取的 guid 作为第一个参数传递,将 1(意味着一次单击)作为第二个参数传递。最后,将您的浏览器重定向到要加载的文章的位置。
现在,可以测试这个应用程序了。由于您处理的是实时数据,因此您必须连接到互联网。建立连接之后,将浏览器指向 http://localhost/clicktrack.psp。因此,应该出现一个包含指向 OTN 最新文章的三个链接的简单 Web 页面。如图 2 所示。
图 2:这是加载时的应用程序页面。

单击任一文章链接并查看所发生的情况。从用户的角度,您将只看到文章正加载到浏览器中,如图 3 所示。
图 3:当跟随应用程序页面上的文章链接时,用户只能看到文章本身。
负责收集有关单击信息的代码将在后台运行。为了确保该代码已经这样操作,您可以连接到基础数据库并发出以下查询:
SELECT * FROM otn_articles_rss;
甚至在完全加载文章文档之前,上述代码应该输出一个包含有关正在加载的文章信息的行,在 clicks 字段中显示 1。随后对此链接进行的每个单击将使 clicks 字段的值增加 1。
#p#
采用Pythonic 方法
在前面部分中编写的代码结构与采用 Pythonic 方法实现的代码看起来不太相同。尤其是,您按照一定的顺序实现了一组将从在 HTML 中嵌入的代码调用的函数,将一个函数返回的结果用作另一个函数的参数。实际上,这是采用任何其他脚本语言(比如说 PHP)结构化您的代码的方式。
尽管 Python 的真正功能在于它能够隐藏令人厌烦的实现详细信息,从而提供一个简单、优美而有效的编码解决方案。字典、列表和列表内涵是常用的 Python 内置类型,在处理结构化数据时可以显著简化您的代码。返回在前面部分中讨论的 oraclepersist.py 脚本,对其进行升级,以便最大程度地利用这些杰出的 Python 语言工具。为了避免混淆,您可以将修订保存在一个单独的名为 oraclepersist_list.py 的文件中:
import cx_Oracle import urllib2 |
从以上代码可以看出,利用列表内涵(一种非常有效的结构化应用程序数据的机制)可以显著减少代码总量。此外,客户端也不必显式调用模块函数。因此,您现在可以重新编写按照前面部分所述嵌入在 clicktrack.psp 中的 Python 代码块,如下所示:
... |
尽管现在它更为简洁,但用户不需要进行任何更改。
但是,有人可能会说将 PSP 页面中的代码与其后端连接实在不是一个灵活的方法。例如,将要显示的链接数量以及要使用的 RSS 地址硬编码到 oraclepersist_list.py 脚本中,借助这个新的语法,您无法根据需要动态更改这些参数。要解决此问题,可以将列表内涵封装在 oraclepersist_list.py 脚本中的某个函数中,如下所示:
... |
正如您所见,以上代码仍然利用了基于使用列表内涵、列表和字典的高级语法,从而允许在 clicktrack.psp 页面中动态更改参数。以下代码片段将阐释现在如何显式指定要显示的文章链接数量:
... |
使用面向对象的方法
尽管 Python 中的面向对象编程 (OOP) 是完全可选的,但利用该范例可以最大程度地减少冗余,高效地自定义现有代码。与其他现代语言一样,Python 允许您使用类封装逻辑和数据,简化了数据定义和数据操作。
回到在前面部分中讨论的 oraclepersist_list.py 脚本,将 processClick 函数替换为如下所示的 HandleClick 类:
... |
假设您将修订保存在 oraclepersist_class.py 文件中,更新后的 dispatcher.psp 现在可能如下所示:
... |
下面您创建 HandleClick 类的一个实例,然后调用它的 processClick 方法,正确传递参数,就像您之前所做的那样。
在此处所讨论的 HandleClick 类中,特别令人感兴趣的是特殊类方法 methods __init__ 和 __del__ 的使用。与其他特殊方法一样,您从不直接调用它们。相反,Python 隐式调用它们以响应在实例生命周期期间发生的某些事件。因此在创建实例时调用 __init__ 构造函数,在销毁实例之前调用 __del__ 析构函数。
在上面的示例中,您在构造函数中连接到数据库并在析构函数中关闭该连接。但在某些情况下,采用这些方法实现更多操作可能是非常令人感兴趣的。例如,您可能希望在销毁实例之前从析构函数中发出 SQL 语句。以下代码片段将阐释如何重新编写 HandleClick 类,以便从析构函数中而不是从某个显式调用的类方法中调用 count_clicks 存储过程:
... class HandleClick: |
正如您所见,更新的 HandleClick 类中不再有 processClick。相反,客户端代码应调用 addArticleClick,该函数用要传递给 count_clicks 存储过程的参数填充该类的属性 params dictionary,将从析构函数中调用 count_clicks 存储过程。因此,现在您可以重新编写嵌入在 dispatcher.psp 页面中的 Python 代码块,如下所示:
... |
注意,此处使用 del 语句取消包含绑定对 HandleClick 类的某个实例的引用的 h 变量。由于这是对该实例的唯一引用,因此之后 Python 将使用一种名为垃圾回收的机制隐式删除该实例。删除后,将自动触发 __del__ 析构函数,执行 SQL 语句,然后关闭连接。
上面的示例极好地说明了采用 Python 开发面向对象的代码时使用特殊方法可以获取的优势。在这个特殊示例中,客户端代码只负责为要针对数据库发出的查询设置参数,而 Python 隐式执行其余操作。
结论
正如您在本文中所学到的,开发一个可扩展的数据库驱动的 Web 应用程序需要进行较良好的规划。继续构建应用程序组件和编写代码之前,您必须首先决定可以在数据库中实现的应用程序逻辑的数量以及可以在前端层实现的操作。
设计文章示例时,将一些数据处理逻辑放到数据库中,实现几个 PL/SQL 存储过程。在这里您学习了如何使用 Oracle XML DB 特性从网页中获取 XML 数据,然后从获取的 XML 文档中提取所需的信息。然后,构建一些 Python 代码,用以编排存储过程所执行的完整操作流。依次从构建的 PSP 页面中调用这些 Python 代码,以实现应用程序的前端层。因此,您获得了相应的应用程序,该应用程序从网页中获取某些实时数据,并跟踪用户在您站点上的活动,将该信息存储在数据库中。在 Python 端,您看到了如何使用 Python 语言的内置工具获取、保留以及操作结构化数据,这些工具包括:列表、字典和列表内涵。您还了解了在将应用程序逻辑和数据封装到类中时如何利用 Python 的面向对象的特性。
【编辑推荐】











