












FILESTREAM简介
FILESTREAM是SQL Server 2008中的一个新特性,允许以独立文件的形式存放大对象数据,而不是以往一样将所有数据都保存到数据文件中。以往在对业务系统的文件进行管理时有两种方法,一种是将文件保存到服务器文件系统中,数据库中只保存了该文件的路径,在使用该文件时应用程序连接到服务器读取文件;另一种是将文件以varbinary(max)或image数据类型保存到SQL Server中。而SQL Server 2008提供了FILESTREAM,结合这两种方式的优点。
FILESTREAM使SQL Server数据库引擎和NTFS文件系统成为了一个整体。Transact-SQL语句可以插入、更新、查询、搜索和备份FILESTREAM数据。FILESTREAM使用NT系统缓存来缓存文件数据。这有助于减少FILESTREAM数据可能对数据库引擎性能产生的任何影响。由于没有使用SQL Server缓冲池,因此该内存可用于查询处理。
在SQL Server中,BLOB可以是将数据存储在表中的标准varbinary(max)数据,也可以是将数据存储在文件系统中的FILESTREAM varbinary(max)对象。数据的大小和应用情况决定您应该使用数据库存储还是文件系统存储。如果满足以下条件,则应考虑使用FILESTREAM:
◆ 所存储的对象平均大于1MB。
◆ 快速读取访问很重要。
◆ 您开发的是使用中间层作为应用程序逻辑的应用程序。
对于较小的对象,将varbinary(max)BLOB存储在数据库中通常会提供更为优异的流性能。
FILESTREAM存储以varbinary(max)列的形式实现,在该列中数据以BLOB的形式存储在文件系统中。BLOB的大小仅受文件系统容量大小的限制。文件大小为2GB的varbinary(max)标准限制不适用于存储在文件系统中的BLOB。
若要将指定列使用FILESTREAM存储在文件系统中,对varbinary(max)列指定FILESTREAM属性。这样数据库引擎会将该列的所有数据存储在文件系统,而不是数据库文件中。
FILESTREAM数据必须存储在FILESTREAM文件组中。FILESTREAM文件组是包含文件系统目录而非文件本身的专用文件组。这些文件系统目录称为“数据容器”。数据容器是数据库引擎存储与文件系统存储之间的接口。
使用FILESTREAM存储时,需要注意以下内容:
◆ 如果表包含FILESTREAM列,则每一行都必须具有唯一的行ID。
◆ 不能嵌套FILESTREAM数据容器。
◆ 使用故障转移群集时,FILESTREAM文件组必须位于共享磁盘资源上。
◆ FILESTREAM文件组可位于压缩卷上。
使用FILESTREAM
在开始使用FILESTREAM之前,必须在SQL Server数据库引擎实例中启用FILESTREAM。具体启用数据库实例FILESTREAM的操作如下:
(1)在SQL Server配置管理器中打开SQL Server数据库引擎的属性窗口,切换到FILESTREAM选项卡,如图所示:
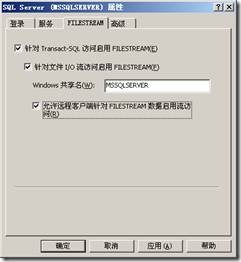
(2)选中“针对Transact-SQL访问启用FILESTREAM”复选框,其他的选项是针对Windows进行读写的,可以都选中,然后单击“确定”按钮保存对FILESTREAM的设置。
(3)打开SSMS连接到数据库实例,右击数据库实例,选择“属性”选项,系统将打开SQL Server实例的属性窗口。
(4)切换的“高级”选项页,在文件流访问级别下拉列表框中选择“已启用完全访问”选项,如图所示:
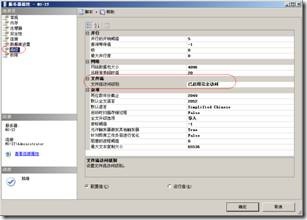
#p#
(5)单击“确定”按钮,然后重启数据库实例,FILESTREAM在数据库实例中设置完成。
在启用了数据库实例的FILESTREAM后,接下来就需要设置数据库的FILESTREAM和创建具有FILESTREAM数据列的表:
(6)对应新建的数据库,则在创建数据库时创建FILESTREAM文件组,如果是现有数据库,则使用ALTER DATABASE添加FILESTREAM的文件组,例如对TestDB1数据库添加FILESTREAM的文件组,具体SQL脚本如代码:
ALTER DATABASE [TestDB1] ADD FILEGROUP [FileStreamGroup] CONTAINS FILESTREAM --添加FILESTREAM文件组 GO ALTER DATABASE [TestDB1] ADD FILE ( NAME = N'FileStream', FILENAME = N'C:\FileStream) --添加FILESTREAM文件 TO FILEGROUP [FileStreamGroup] GO |
系统将自动创建C:\FileStream文件夹并在其中写入filestream.hdr文件,该文件是 FILESTREAM容器的头文件不能删除,一定要确保在运行该语句之前C:\FileStream并不存在。
(7)创建了FILESTREAM文件组后便可创建和修改表,指定某varbinary(max)类型的列包含FILESTREAM数据。例如创建Files表,该表包含FileID和FIleContent列,具体脚本如代码:
CREATE TABLE Files |
管理与使用FILESTREAM
在创建好FILESTREAM表后即可向其中添加、修改和读取数据。SQL Server支持使用T-SQL和WIN32 API两种方式访问FILESTREAM。
对于T-SQL访问FILESTREAM数据列来说,FILESTREAM是完全透明的,也就是说,T-SQL仍然使用一般的访问varbinary(max)数据列的方式访问,并不会因为是FILESTREAM列而有所不同。
例如向Files表中插入数据、修改表数据和删除数据的SQL脚本如代码:
INSERT INTO Files --插入测试数据 UPDATE Files --更新测试数据 DELETE FROM Files --删除测试数据 |
无论是插入数据还是修改数据,SQL Server都将在文件系统中创建新的文件来保存***的修改文件内容,修改或删除数据后文件系统中的文件将保留,而不会被同时删除。
使用FILESTREAM来存储二进制大型对象(BLOB)数据时,可使用Win32 API来处理文件。为了支持在Win32应用程序中处理FILESTREAMBLOB数据。所有FILESTREAM数据容器访问都是在SQL Server事务中执行的。可在同一事务中执行T-SQL语句以保持SQL数据和FILESTREAM数据之间的一致性。
【编辑推荐】










