












我在过去的几年中领导过一个程序构建小组,在这段时间内我亲眼目睹,软件从概念到代码再到用户的方式,已经发生了相当多的变化。特别需要指出一点,用于管理大规模软件开发项目的构建活动的工具和技术,已经发生了非常大的变化。
在20世纪90年代中期,大多数源代码都是用 C 或是 C++ 编写的。要描述并管理代码的编译过程,可供选择的工具就是 make , 再加上零星几个批处理文件或是 shell 脚本以增加自动化程度,您的构建过程也就这样了。
现在时代已经变了。出现了 Java 技术、XML、XSLT、极限编程与持续构建、还有很多其他的新技术新思想。到90年代后期,情况出现了很大的变化。在程序构建工具集中,最大的变化也许就是增加了 Ant。
Ant 是一种基于 Java 的程序构建工具。它来自 Apache Software Foundation 的 Jakarta 项目,已经成为构建 Java 项目的事实标准。Ant 脚本的结构,以及它的很多易用特性,都源于 XML。同时,因为 Ant 脚本用 XML 表示,所以可以对其进行解析、修改、生成,或是用可扩展样式表语言转换(eXtensible Stylesheet Language Transformations,XSLT)进行程序转换。您甚至可以从一个 Ant 任务内部调用样式表处理器(查阅 参考资料中有关 Ant 样式任务的描述)。
两个人才能跳出优美的探戈!
现在我们要考虑 Ant 与 XSLT 结合的情况。本文剩余部分将着眼于三个实例,每一个都阐述了我在工作中遇到的某个问题。在每一个例子中,我描述的解决方案的基本思路都是将一个基本的 Ant 脚本与一个或者多个 XSL 样式表相结合。XSLT 使得原本是静态的脚本变得灵活。请根据您的经验考虑一下 Ant 在这些情况下的用法:
◆ 如何简化脚本的维护过程
◆ 如何根据 XML 元数据创建复杂的脚本
◆ 如何实现脚本浏览器
问题的价值体现在解决方法中。您也许会觉得每个特定的例子对您都没有什么用处,但是我相信您可以找到自己的办法,用这样一种简单的技术使您的构建过程充满活力。
通过实例学习
在我们开始之前,我想确认一下您是否理解一些基本概念。我提供的每一个解决方案都要求进行一次 XSL 转换。图 1 描述了 XSLT 工作的一般方式。在本文的场景中,source document(源文档)通常是一个 Ant 脚本,但是有时候可能是另一个 XML 数据文件。transformation process(转换过程)将 stylesheet(样式表)中的规则应用到源文件上,并生成 result document(结果文档)。
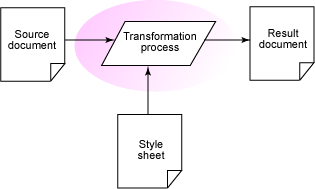
图 1. XSLT 过程概览
例 1: 用样式构建程序
前面提到过,我在一个程序构建小组中工作了若干年。我的团队与许多不同的开发组织接触,支持他们进行程序构建。我曾经同时支持过多达 17 种不同的产品,并为一个不断变化的软件提供将近50个发布版本。
我们所面临的挑战之一就是对如此之多的活动及其多样性进行管理。通常情况下,开发团队的共性很少,相互之间也没有交互。因此标准化就成为解决问题的关键。从抽象的层次来看,我们的构建过程在每一次发布时都是相同的:
◆ 定义您计划构建的内容;
◆ 将源代码提取到用于构建的计算机上;
◆ 运行编译和打包的子过程;
◆ 发布构建结果;
◆ 通知大家构建已经就绪。
我们原先打算开发通用的脚本,即便不是全都一样,至少也要遵从所有的要点。由于有这么多不同的设计,问题也层出不穷。一段时间以后,这些脚本如果不严加看管,就开始向不同的方向漫开了。每一个脚本都变得更加特殊。而一般的维护过程要花费大量的人力、时间和协调工作。
#p#
解决方案
最近,我们决定重新制作脚本,要巩固 Ant 作为主要脚本工具的地位。我们首先对一个缺省的构建过程达成一致,此后,对前面列出的这些一般性任务进行精炼,划分成更小的步骤,每一个步骤都表示一个工作单元,对多个构建过程而言,工作单元可能是通用的。对于这个精炼过的过程来说,每一个步骤都实现成一个或者多个 Ant 目标,每一个目标都具有缺省的行为,适应于大多数情况。在侧栏“构建脚本的要点”中,我们给出了实际的操作顺序,其中每个步骤都是用 Ant 目标名表示的。
这些要点对于每一个构建过程都是适用的,但是对于某个特定的步骤,缺省的的行为可能并不适用。这也就是 XSLT 可以增强灵活性的地方。如果不具备对缺省脚本进行转换的能力,我们可能还是得为几乎相同的脚本维护多份拷贝。最好变成每一次构建过程都实现一个局部的脚本,其中包含的步骤只对这个过程有效。我们设计了一个前端过程(也是一个 Ant 脚本),它运行样式表,将输入文档转换成 Ant 的 build 文件。如果在这个局部脚本中没有涉及那些步骤,那些步骤就使用缺省的定义。
这个过程可以用下面的公式来表示:
局部目标 + 缺省目标 + 样式表 = build 脚本
局部目标包含在输入转换过程的主要 XML 文件中。转换过程从次要输入文档中读取缺省目标,将结果合并,并在合并的过程中指明对局部脚本的引用。
清单 1 显示了 Ant 中的 <style>任务,它负责运行转换过程。
清单 1. Ant 的 style 任务
<style in="${local_targets}"
out="${build_script}"
style="${style_sheet}"
force="yes">
<param name="defaults" expression="${default_targets}"/>
</style>
|
缺省的“targets”文档不是真正的 Ant 脚本。其中并不包含 <project> 标签,只是通过 <default> 标签将 Ant 目标按照每一种缺省情况分组。这样每一组目标就可以定义一个独立的步骤(见清单 2)。
清单 2. 构建 defaults XML 示例
<defaults> |
如果要进行一般性的功能增强,只需对缺省目标,或是样式表进行修改。由于所有的过程都引用同一份缺省目标或样式表,因此所作的改动会在运行过程中自动应用于所有的脚本。维护工作中还剩下一个问题需要考虑,即局部脚本覆盖了通用步骤中的某个增强特性的情况。然而,如果对设计进行细心地管理,根据我们对步骤的定义,那些可能会被覆盖的步骤应该不会包含任何缺省的行为。
例 2: 用 XSL 查看 Ant 脚本
有一个问题我经常会遇到,即,必须去理解和修改别人写的脚本。脚本中经常会充斥着由本该去写源代码的人编写的构建过程。再加上缺乏文档,甚至某些文档还会产生误导,这些脚本就更加声名狼藉了。
好的文档是无法取代的,如果没有这样的文档,只要能用一种抽象的方式浏览整个过程,那么也可以抵消一些负面影响。只要您知道一些引用关系,然后在脑海中建立一个框架,这些就可以指引您继续研究了。如果有了好的浏览器,您就可以看到一幅概念的视图,可以自由地浏览,而不必担心忘记前后关系。您可以不仅可以看见森林,还可以看见一棵棵树。
如果您第一次看见一个很大的 Ant 脚本,您很可能会被它吓退。即使您对这个脚本很熟悉,也要花很多时间才能确定需要修改的地方在哪里。所有的 XML 文档,包括 Ant 脚本在内,都是高度结构化的。只要有 XSLT,您就可以将 Ant 脚本的这种结构化特性转换成 HTML 文档,这样文档就变得更加容易阅读和理解。您可以用 XSL 过滤掉无关紧要的信息,只留下重要的元素。
如果您使用的浏览器支持 XSL 样式表(比如 Microsoft 的 Internet Explorer 6),您甚至可以使您的 Ant 脚本永久保持这样的特性。没有混乱的场面,也不要大惊小怪,您只需要直接打开 Ant 脚本,就可以在浏览器中查看结果了。Ant 在执行的过程中会忽略额外的处理指令,这样您就没有必要在一开始就单独生成 HTML 文件。
眼见为实
第一个步骤是开发样式表,用于将 Ant 脚本转换成 HTML。样式表可以很简单,也可以很详尽,这取决于您的意愿。不论好与坏,这里就是我开发的样式表了,它能够满足我在查看 Ant 脚本时的基本需求:
◆ 提供内容列表,方便用户迅速地找到脚本中相应的节
◆ 对使用到的所有属性和目标都按字母排序并分组
◆ 在目标及其所依赖的部分之间提供导航链接
◆ 显示构造出某个特定目标的任务
如果您对 HTML 或者是 JavaScript 比较熟悉,那么毫无疑问,您对于格式化和显示数据的方式肯定有更富创造性的见解。
您准备好样式表之后,可将其放在某个浏览器能够访问的地方。可以是在 HTTP 服务器上,或是在共享设备上,只要方便就可以了。最后一步是向 Ant 脚本中加入指令。这些指令告诉浏览器在显示该文档的时候使用您的样式表。否则,您只能看到五颜六色的原始 XML 代码。千万别眨眼!不然就忘记这一步了。您准备好了么?请将清单 3 中高亮显示的部分拷贝到 Ant 脚本的最上面,然后用您的样式表的位置替换 href 属性的值。
清单 3. 样式表处理指令
<?xml version="1.0"?> |
这样就处理完了。
正如前面一个例子里所讲的,因为样式表是与数据(在这里是 Ant 脚本)分开的,您不管如何增强样式表,都没有必要对脚本进行修改。只要将修改过的样式表部署好,所有的用户立即就能用到新的样式。
如果您能够浏览格式化之后的 Ant 脚本,您也许会想,为什么我没有用框架让浏览变得简单些呢?从一个样式表中生成多个框架可没有您想象的那么简单,需要用脚本语言实现(如 JavaScript)。不过我们还是可以实践一下。我加入了同一个 Ant 脚本的第二个实例,这次用 一个可以生成框架的样式表来格式化。这个样式表用到了 JavaScript、MSXML、和 ActiveX 控件,因此要求用 Microsoft Internet Explorer 作为浏览器。Jeni Tennison 的书(参阅 参考资料)中第 14 章对于完成这个例子会有特别的帮助。
#p#
例 3: 用 XSL 扩展 Ant
Ant 的语法与其他所有的指令集相似,都不能表达某些特定的概念。虽然 Ant 对依赖关系、引用关系以及继承关系都处理得很好,但是却不支持最基本的循环。原有的标签集没有提供任何可以反复执行一组任务的手段。
问题
请考虑一个很简单的问题。假设您正在构建的一个发布版本支持八种语言:德语、英语、法语、意大利语、日语、韩语、葡萄牙语以及西班牙语。与特定语言相关的文件必须要用其本国代码表示,这就要求对所有与特定语言有关的属性文件都运行 Ant 的 native2ascii 任务(参阅 参考资料)。这听起来用循环挺合适的,是吧?
下面是解决这一问题的三种方案:
解决方案 1: 暴力方法
暴力方法就是反复编写任务代码,直到需要的次数。这种方法可以达到目标,对于次数较少的迭代而言也还不错。但是如果循环变得更大,迭代的次数很多,那么维护这段代码就成问题了。每一块重复的代码都使得程序逻辑中出现错误的几率增加。在本例中,任何修改(如增加新的属性文件)都要放大八倍。清单 4 显示了使用这种方法的情况。请注意,黑体标识的部分强调了每一组代码之间的细微区别。
清单 4. 暴力方法
<target name="convert_native_encodings">
<native2ascii encoding="
Cp850" src="${basedir}/src" dest="${basedir}/export">
<include name="**/
*_de.properties/>
</native2ascii>
<native2ascii encoding="
Cp850" src="${basedir}/src" dest="${basedir}/export">
<include name="**/
*_en.properties/>
</native2ascii>
<native2ascii encoding="
Cp850" src="${basedir}/src" dest="${basedir}/export">
<include name="**/
*_es.properties/>
</native2ascii>
<native2ascii encoding="
Cp850" src="${basedir}/src" dest="${basedir}/export">
<include name="**/
*_fr.properties/>
</native2ascii>
<native2ascii encoding="
Cp850" src="${basedir}/src" dest="${basedir}/export">
<include name="**/
*_it.properties/>
</native2ascii>
<native2ascii encoding="
SJIS" src="${basedir}/src" dest="${basedir}/export">
<include name="**/
*_ja.properties/>
</native2ascii>
<native2ascii encoding="
KSC5601" src="${basedir}/src"
dest="${basedir}/export">
<include name="**/
*_ko.properties/>
</native2ascii>
<native2ascii encoding="
Cp850" src="${basedir}/src"
dest="${basedir}/export">
<include name="**/
*_pt_BR.properties/>
</native2ascii>
</target>
解决方案 2: <for> 标签
更好的解决方案是给 Ant 提供一个 <for> 标签。经过恰当设计的扩展机制可以增强语言的功能。清单 5 显示了这种解决方案的情况。然而,这种方法并不是没有一点儿缺陷。首先,它要求对 Ant 的工作原理有比较深入的理解,这样才能实现新的标签。第二个问题同样是维护的问题,这个问题也更值得关注。在运行的时候 Ant 必须能够访问支持新标签的类。这就要求使用一个独立的 .jar 文件,或者对 Ant 重新打包。每一个运行这段脚本的系统都需要访问新的标签。
清单 5. 一种更好的方法
<!-- Iterate over each language code --> |
encodings.properties 文件的用处是创建从语言代码到编码单元的映射:
清单 6. 编码映射
# File: encodings.properties |
解决方案 3: 使用 XSLT
最后一种方案和第二种方案一样,也是要扩展 Ant 语言,但是不会引起维护的问题。我这次没有在 Ant 内部创建新的 Java 类来扩展 for 循环,而是用 XSLT 完成同样的工作。得到的结果是可以在 Ant 中运行的脚本。样式表仅仅将 <for> 标签展开为一系列的任务,这一点又类似于第一种方法。
这种转换所用的样式表十分简单明了。缺省的模板输出的 XML 与输入的一模一样,我们也没有必要进行任何修改。只有当出现 <for> 标签的时候才会有不一样的输出。您可以查看这次转换采用的完整 样式表 。
有一点值得关注一下,即,最初的输入并不是有效的 Ant 脚本;它的输出才是有效的 Ant 脚本。当您发布程序构建的结果时,只需要发布最后得到的脚本即可。这个脚本是完全合法的 Ant 脚本,大部分开发人员不需要使用样式表,直接运行得到的脚本就可以了。
结束语:新与旧总是相对的
我希望您认为这些信息是有用的,不管是直接使用,还是点燃您自己的思维火花。我在许多方面都只是在重新表述一种很陈旧的想法。自从最早的编译语言时代开始,人们就已经在编译之前用模板对源代码进行预处理了。即便是今天,这仍然是一种功能强大的技术。
针对这项技术还可以研究和开发更多的应用程序。我最后留给您一些建议,目的只是为了让“Ant(蚂蚁)”能继续翩翩起舞。请尽情享受其中的快乐吧!
您可以考虑用样式表根据其他的 XML 数据文件生成 Ant 脚本。比如说,我们所写的很多 Java 代码都是通过一种插件架构来打包和发布的。这就要求包中具有 plugin.xml 文件。要将插件组装进来,会用到一些基本的 Ant 任务( <javac> 、 <jar> 、等等)。为什么不利用 XSLT,把 plugin.xml 这个描述文件转换成构建插件的 Ant 脚本呢?
假设您希望在构建过程执行的时候实时地获得其状态,比如说实时更新某个 Web 页面。有一种实现的方法是为 Ant 编写一个日志任务,在每一个目标开始或结束的时候执行更新。同样,这样就要求深入理解 Ant,并具有某些 Java 技能。还有一种简单点儿的方法,我们可以用 XSLT 在每一个目标开始或者结束的时候插入一项探测任务(probe task)。这些探测任务起到了跟踪点的作用,用已有的 Ant 任务,通过将数据写入文件的方式来获取状态。
【编辑推荐】












