自从我上次斗胆回答“如何选择数据挖掘工具”之后,已经好几年过去了。本文主要阐述以下两个核心观点:
1. 没有***的工具,更确切地说,没有适合所有人的***的工具。
2. 最有用的工具,是那些能够满足你所需要的绝大多数数据挖掘任务的工具。
主要的数据挖掘任务
大多数数据挖掘人员都明白,数据挖掘项目中70%到90%的工作是做数据准备。在数据挖掘工具的演进过程中,数据准备功能的开发一直被放在次要位置上。***,你要能够对模型准确评估,才能比较多个模型,并将它们推荐给市场人员。
数据准备任务
常见的数据准备任务包括:
◆进行数据评估
以判别出:
缺失值(空字符串、空格、空值)
孤立点
共线性评估(自变量之间的相关性)
◆合并多个数据集;
◆从不同输入格式到通用分析格式的元数据(字段的名称和类型)映射;
◆将类似变量的值变换为通用格式;
◆某些算法对输入变量有特殊要求,需要将数值型变量变换为类别型(通过数据分箱和分类),或者将类别型变换为数值型;
◆将变量值切分为多个字段,或将多个字段合并为一个字段;
◆从现有变量中派生新变量。大多数数据挖掘人员发现,有些***有预测能力的变量,正是派生出来的变量。
大多数数据挖掘工具会把这些数据挖掘功能放在次要的地位, 本文则会侧重评估常见数据挖掘工具处理这些任务的能力。
除了能支持以上的数据准备任务,一个好的数据挖掘工具还应该包含模型评估的功能,以便比较建模过程中产生的多个模型,并用于支持直效营销(direct marketing)。
#p#
模型评估工具
在分析理论中,***的模型是具有***精度的模型,可以准确预测出目标变量的类别,同时在验证数据集上也能表现稳定。这就是说,在预测中我们要考虑响应目标和非响应目标的组合精度。这种方法称为全局精度方法(Global Accuracy method)。大多数数据挖掘工具使用这种方法来确定“***”模型。但是,它也有美中不足。全局精度评估方法的背后有一个前提假设,就是各种分类错误的代价是相同的。这种方法在课堂上表现不错,但在实际的CRM数据挖掘应用上则可能存在问题,特别是在那些用于直邮营销的应用上。实际上,这也是过去很多用CRM来支持直邮营销而未能产生明显商业价值的一个主要原因。对模型的评估有一些主要原则,而其中只有一部分是营销部门真正关心的: ***化目标客户的响应率,最小化所需成本。大多数数据挖掘工具都把注意力集中在预测的组合精度上,却完全忽略了成本的因素。
在直效营销活动中,向未响应的潜在客户(称为“错误肯定”错误,false-positive)发送邮件的成本是相当低的;而如果一个潜在客户可能会响应(称为“错误否定”错误,false-negative),你却没有向他发送邮件,那么这个代价就相当大了(因为没有把他发展为客户,您会损失他所缴纳的会员费,而且他也不可能购买您的其它服务)。因此在直销营销模型的评估中,就应该尽量最小化错误否定的错误,而不是错误肯定。因为营销部门只关注响应率和成本,如果前30%的客户名单中包含了全体响应者的60%,就可以满足他们的需求。对于直销营销来说,尽管前30%的客户仍会有部分人不会响应(错误肯定错误),向他们发送邮件依然是值得的。那是因为我们已经联系了全体响应者中的60%。 此时就比随机发邮件的有效性提高了一倍,也就更加合算。
大多数数据挖掘工具都使用全局精度方法来进行模型评估。它们可能会要求你使用这种方法,通过工具的报表功能来识别出“***”模型。不同算法会产生多个模型,我们不应该只是查看工具提供的精度报告,简单比较后就判别哪个是***的模型。实际上,更合适的评估应该根据如下条件来做出:按照预测概率值顺序排列模型结果,生成评分列表,然后看真正的响应者是否被放在最前面的分段中。 尽管分类算法可以输出分类概率,实际的类别(例如,0或1)还是对分类概率的进一步归纳(例如,<0.5 = 0; ≥ 0.5 = 1)。 大量真正的“金块”隐藏在数据挖掘工具的功能模块之中。 初级的CRM挖掘人员会把注意力放在分类和精度上面,但真正的“金块”应该是客户保持、购买倾向以及新客户获取的概率值。
我们应该查看累积提升表(cumulative lift table;例如表1),来判别模型是否真正有效地把正确肯定(true-positives)放在了靠前的分组里。累积提升表可以通过以下方式创建:
1.预测概率值按降序方式存储为有序列表
2.把这个有序列表划分为10段(分组)
3.计算每组中的实际命中数(actual hits,实际的响应数)
4.计算每个分组的随机期望值(random expectation),该期望值等于实际响应总数除以10。也就是说,在每个分组中我们期望会有实际响应总数的10%会响应。 如果命中率超过了随机期望值,就意味着模型为该分组带来了提升。
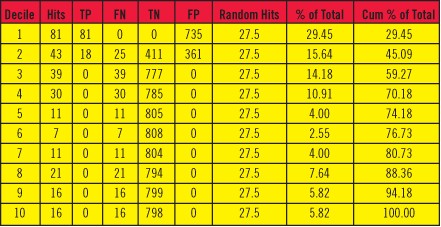
表1: 提升表
译者注:
Decile-分组序号;Hits-命中数,即每组内包含的实际响应数,等于TP+FN;
TP-正确肯定;FN-错误否定;TN-正确否定;FP-错误肯定;
(TP和FN对应于实际的响应,TN和FP对应于实际的非响应)
Random Hits-随机命中数,即随机期望值,等于SUM(TP+FN)/10;
% of Total-召回率,等于Hits/SUM(Hits)*100;
Cum % of Total-累积召回率,是% of Total的累积值。
一共划分了10个分组,实际的总响应数为SUM(Hits)=275,因此每组的随机期望值为275/10=27.5。***组的命中数为81,明显超过了随机期望值,其召回率=81/275=29.45%。第二组的命中数为43,也超过了随机期望值,其召回率为43/275=15.64%,累积召回率等于第二组的召回率加上前面所有组(即***组)的召回率,等于15.64%+29.45%=45.09%。
从上表中可以看出,该模型划分肯定和否定的阈值应该是在第二个分组中,这样才出现了***组都被预测为肯定,但其中有81个是正确的肯定(TP),而735个是错误的肯定(FP);第二组中则同时包含了TP、FN、TN和FP;从第三组之后则都被预测为否定(因为位于阈值之下),因此包含了FN和TN。
正确肯定(True-Positives,TP): 实际的响应中,被正确预测为响应的个数
错误否定(False-Negatives,FN): 实际的响应中,被错误预测为非响应的个数
正确否定(True-Negatives,TN): 实际的非响应中,被正确预测为非响应的个数
错误肯定(False-Positives,FP): 实际的非响应中,被错误预测为响应的个数
通过对提升表的分析可以看到,在第四个分段之后,增量提升(incremental lift,第8列中的”% of Total”)下降到随机期望(每个分段为10%)之下,而前四个分段包含了超过70%的响应。 从下面的增量提升曲线(图1)中可以明显看出增量提升和随机期望的交叉点。
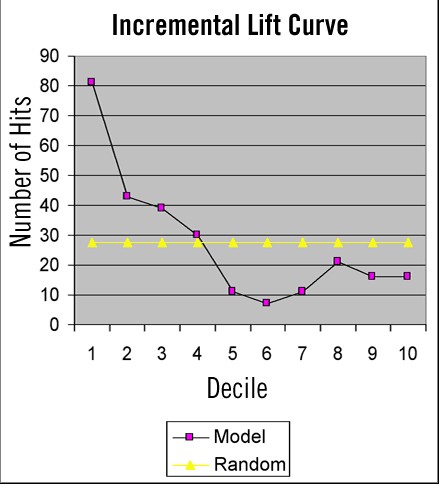
图1: 增量提升图示例
在增量提升曲线中标示了各个分段的命中数。 在图1中可以看到,增量提升曲线在第4个分段后和随机期望线(275个响应的10%,即平均每个分段27.5个响应)交叉。 不管营销经理怎么去看,上述的表格和图形都可以把必要的信息传递给他们。 营销人员可以借助模型评估工具,来设定要给多少个客户发邮件。 以表1为例,营销人员可以向前四个分段的客户(占整个评分名单的40%)发邮件,并预期可以命中70%的潜在响应客户。
我们现在已经了解该如何评估数据挖掘模型,接下来就可以深入分析和调整业务流程,借助模型的结果来提高企业的盈利。 业务流程包括:
1.数据挖掘过程
2.知识发现过程
3.业务流程管理(BPM)软件
4.知识管理系统
5.商业生态系统管理
#p#
数据挖掘过程
Eric King在“如何在数据挖掘上投资:避免预测型分析中昂贵的项目陷阱的框架”一文(发表于2005年10月的“DM Review”)中主张数据挖掘是一段旅程,而非终点。他把这段旅程定义为数据挖掘过程。 该过程包含如下要素:
1.一个发现过程
2.具有灵活的框架
3.按照清晰定义的策略进行
4.包含多个检查点
5.多次定期的评估
6.允许在反馈环路中对函数进行调整
7.组织为叠代式的架构
过程模型
很多数据挖掘工具的厂商都对这个过程进行了简化,使之更加清晰。 SAS将数据挖掘过程划分为五个阶段: 抽样(Sample),解释(Explain),处理(Manipulate),建模(Model),评估(Assess)。 过去人们常用循环式的饮水器来比喻数据挖掘过程。 水(数据)首先涌上***层(分析阶段),形成漩涡(精炼和反馈),等到聚积了足够多“已经处理过”的水之后,就溢出来流到下一个更低的层中。 不断地进行这种“处理”,直到水流到***层。在那里它被抽回顶层,开始新一轮的“处理”。 数据挖掘和这种层次式的叠代过程非常相像。 甚至在很多数据挖掘算法的内部处理也是如此,比如神经网络算法,就是在数据集上多次运行(epochs),直至发现***解。 Insightful Miner已经在其用户界面中内建了简单过程模型。 这种集成可以帮助用户把必要的数据挖掘任务组织起来,让任务能够按照正确的顺序来处理。
但使用饮水器来比喻数据挖掘过程还不算恰当,因为它没有反映出反馈环路,而反馈环路在数据挖掘过程中是很常见的。 例如,通过数据评估可以发现异常的数据,从而要求从源系统中抽取更多的数据。 或者,在建模之后,会发现需要更多的记录才能反映总体的分布。
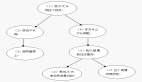
在CRISP过程模型中进行了解决这个问题的尝试,该模型是由Daimler-Benz、ISL (Clementine的开发者)和NCR共同制定的。 CRISP同时也被集成到Clementine挖掘工具(现在属于SPSS公司)的设计中。 CRISP几乎反映了完整的数据挖掘环境。
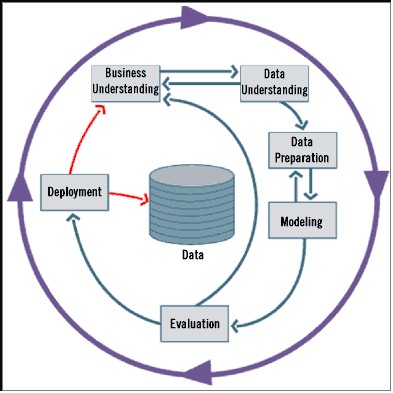
图2: CRISP图例
使用数据建模其实和做陶土模型或者大理石模型差不多。 艺术家首先从一大堆材料开始着手,经过许多次的加工和检查,才诞生了最终的艺术品。很多人在建模过程中常常没有充分理解建模的本质,由此带来了一系列问题,使得建模变得很复杂。 Eric King发现数据挖掘是一个循环的过程(就象上图中的CRISP流程图),而非线性的过程。 这种循环式的数据挖掘过程会让您想起Wankel转式汽车发动机。 这种发动机是一圈一圈旋转的(而非上下运动),不断输出动能来驱动汽车。 与之相似,数据挖掘过程也是不断循环,产生信息来帮助我们完成商业目标。 信息就是推动商业的“能量”。 在挖掘过程中会有很多对前一个阶段的反馈(例如,在完成初步建模之后可能需要获取更多的数据)。
不过,在CRISP流程中还是遗漏了一个要素——那就是对数据仓库或源系统的反馈。 前一次CRM营销活动的结果应该导入数据仓库,为后续的建模提供指导,并能跟踪营销活动间的变化趋势。 我在CRISP流程图中加入了这些反馈,以红线表示(见图2)。
通过数据挖掘过程的结构,我们可以得知数据挖掘工具必需能完成那些任务,但是工具常常会缺少对部分功能的支持。 当产生了挖掘结果时,你会怎么使用这些结果呢? 此外,针对挖掘结果所采取的这些行动又将如何影响后续的挖掘? 数据挖掘工具应该具备的一些功能包括:
1.将模型导出到多种数据库结构中
2.模型的导出格式,适合于决策支持和商业行动的应用
3.挖掘算法的输出数据,可以为另外的算法所用
4.能够比较不同算法的结果
【编辑推荐】