












Oracle 发布了 PL/SQL 和 Java 应用编程接口 (API) 后,市场上才会推出可利用这一新发布的 API 的点击工具或构建器,这一般是***的做法。利用这一实践,开发人员可将新功能即刻融入其应用程序中以使其企业从中获益。
然而,开发可利用新发布 API 的专门工具需要投入大量精力。因此,理想情况下,从 API 发布直至推出利用该 API 的直观最终用户工具,至少需要数个月,而实际上,这一滞后时间通常为一年或两年。同时,利用 API 可能需要企业使用自己的工具,或更为常见的是利用即席解决方案,例如在报表生成器和电子表格中嵌入对 API 的调用。
一种常用方法是将 API 包装在数个脚本中,然后使用自定义按钮和菜单从电子表格访问这些脚本。但是,这一方法的主要缺点在于如今的电子表格是将单个单元格中的文本和数字作为值来进行处理的,因此它通常不是处理新功能的合适工具。
本文将介绍如何快速将分析和其他 API 整合至一个最终用户可从其中轻松访问新代码的电子表格平台。作为指导性示例,其中还将阐释了如何将Oracle 数据挖掘(PL/SQL) API 重新打包为 Java API,以及如何从电子表格调用的 J Cells 访问该 API。J Cells 完全以 Oracle JDeveloper 编写。它不仅可以将文本和数字作为单元格的值,而且还可将 Java 对象作为值进行处理,并可从其单元格直接访问任何 Java API,以即刻进行部署。
电子表格平台
我使用的是电子表格界面,只是其中允许用户在单元格中创建任何 Java 对象以及使用基元 Java 类型。每个单元格都可用作另一个单元格的变量,用户可以选择在单元格中直接编写 Java 代码,或使用其他格式。将电子表格界面和对象(而不仅是常规电子表格中的数字和文本)使用相结合是自动进行的:J Cells 为每个适合单元格的对象计算指示值,这一指示值给予用户有关显示对象的充足线索。此外,还会实施一个完整的值系统,可根据需要(例如,当用户双击给定单元格时)以各种其他格式显示对象。即使在电子表格中,因为公式可能定义比较复杂,所以系统还需识别要创建的对象是否具有相关的向导。向导通常是一个特定于某个对象类型的图形化代码生成器。稍后本文示例将说明如何在 J Cells 中使用向导。
图 1 显示了本文示例的电子表格界面。
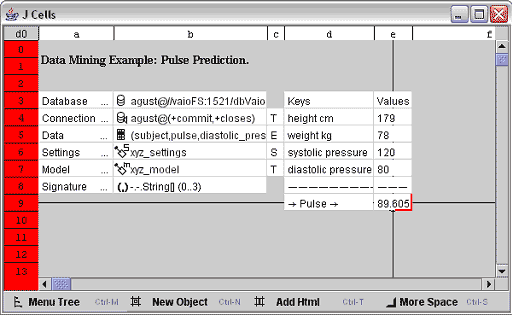
图 1:J Cells 的电子表格界面
#p#
数据挖掘 API
Oracle 支持两种兼容的 API 以访问数据库中的数据挖掘功能。***种是 PL/SQL API,其中包括 DBMS_DATA_MINING 程序包,另一种也是 Java API,称为 Oracle 数据挖掘 Java API。因为 J Cells 目前最适合访问 Java API,所以需要以可直接从 Java 对其进行访问的方式打包 PL/SQL API。两个主要的 Oracle 数据挖掘概念是设置和模型。设置概念基本围绕带有两列(setting_name 和 setting_value)的设置表构建;其中 setting_name 是挖掘算法使用的属性名,而 setting_value 是与该属性相对应的值。
DBMS_DATA_MINING 程序包包含若干过程,包括 CREATE_MODEL 和 APPLY。CREATE_MODEL 过程根据设置表(作为过程的参数之一提供)中的值为给定挖掘函数和数据集创建挖掘模型。该过程简单且易于使用。实际上,由用户来为要创建的模型、要使用的挖掘函数、包含要使用的数据的表、要建模的列以及设置表提供名称。这一方法的优点在于所有不同算法都可以类似的方法调用。每种算法的微调都整合至设置表中,但在很多情况下,各种设置系数可由算法本身自动决定。设置表中条目的复杂性根据用户的专业技术背景和算法而有所不同。许多专业用户可能希望手动设置所有可能的系数,而我们中的多数人更可能乐意系统自动给出适用设置。Oracle 提供了一个要用作设置键的常量列表,以及命名为常量或数字间隔的值。
表 1:algo_name(算法名)设置键的值
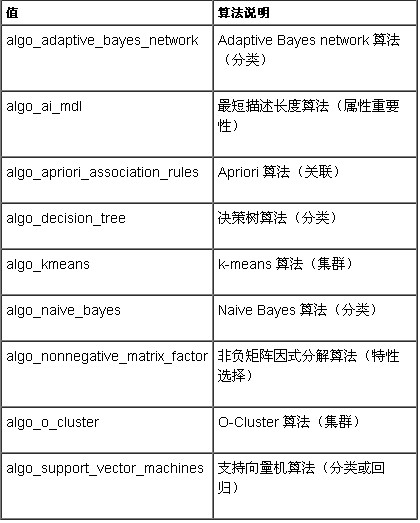
Oracle 的算法名 (algo_name) 键的常量值如上所示。对于其中的每一个值,使用了可能键和值的不同集等。以下(图 2)显示了向导函数是如何将这些键映射到树结构,并允许用户通过操纵该设置树定义设置表的。
作为 Oracle 数据库中创建的挖掘模型,DBMS_DATA_MINING.APPLY 过程用于将该模型应用到新数据集。而且,这是一个易于使用的过程,要求只输入挖掘模型名、包含新数据集的表名、用于识别新数据集中行的列以及结果数据集名。Java 类 OracleMiningModel (below) 在调用预测、评分或 apply 方法时,都会利用该 APPLY 过程。此外,DBMS_DATA_MINING 程序包包含若干根据类型将各个模型详细信息作为结果集或以 XML 格式返回的函数。这些细节函数也可通过使用 OracleMiningModel 类的实例(代表数据库中的不同模型)进行访问。
此处可通过创建一个称为 OracleModelSettings 的 Java 类以 Java 打包 (PL/SQL) 设置概念,该类具有灵活的构造函数和各种签名,包括
public OracleModelSettings ( String modelSettingsName,
Connection databaseConnection,
String[] keyToValueStringMap)
throws SQLException
|
keyToValueStringMap 只是表单“ -> ”的字符串数组。该数组详细说明了设置表的行,以及负责在数据库中维护设置表的类。
类似地,此处也可通过创建一个称为 OracleMiningModel 的 Java 类以 Java 打包模型概念,该类具有构造函数和各种签名,包括
public OracleMiningModel ( String modelName, OracleModelSettings oms, String[] keyToValueStringMap) boolean recreate) throws SQLException |
此处使用 keyToValueMappings 数组来确定在 Oracle 数据库中创建数据挖掘模型所需的算法以及其他命名属性。该类的用途就是创建和维护数据挖掘模型。此外,OracleMiningModel 类还定义了用于检索以及将该模型应用到新数据集的方法。这些方法包括以下各项,此处只显示了一小部分。
public OracleResultSet infoAprioriAssociationRules(int topn)
public OracleResultSet infoAprioriFrequentItemsets(int topn)
public OracleResultSet infoAdaptiveBayesNetwork()
public OracleResultSet infoAIMinimumDescLength()
public OracleResultSet infoKMeans()
public OracleResultSet infoNaiveBayes()
public OracleResultSet infoNonnegativeMatrixFactorization()
public OracleResultSet infoOCluster()
public OracleResultSet infoSupportVectorMachines()
public XMLType infoDecisionTree()
public Object getPrediction(String[] signature, double[] doubleVal)
public HashMap score(String[] signature, double[] doubleVal)
public OracleResultSet apply( String dataTable,
String caseID,
String resultTable,
String schema,
boolean overwrite)
|
除了具有上述签名外,所有的方法可能都会引发 SQL 意外。一旦可以从两个简单类来管理数据挖掘功能后,就可调用该电子表格平台来访问任何可用的数据挖掘算法,以在 Oracle 数据库中建模数据集。
#p#
数据挖掘示例
因此,来看一个在该系统中编写的小数据挖掘模型,该模型可通过访问 Oracle 数据库创建并运行 ODM (Oracle Data Mining) 回归模型。该回归模型的用途是根据输入(例如血压、高度和体重)预测心率。使用 J Cells 可直接访问 Java API 以实例化对象并在对象上调用方法。首先,连接至 Oracle 数据库。DataSource 对象可通过将以下公式
() = ~ OracleDataSource("agust","agust","dbVaio","vaioFS");
输入到电子表格的单元格 b3 中进行实例化。Tilde 符号 (~) 表示缩写符号,允许 J Cells 将(右侧)语句转换为构造函数t“new cell.OracleDataSource( "agust", "agust", "dbVaio", "vaioFS");”,使系统能够以用户“agust”的身份访问服务器“vaioFS”上的数据库“dbVaio”。
现在,可通过在 DataSource 对象上调用正确的方法(例如在单元格 b4 和 b5 中分别输入以下公式),获得数据库连接以及检查数据库中的源数据:
(*) = b3.getConnection();
(*) = b3.query("select * from pulse_clinical");
|
***个语句将向单元格 b4 中返回一个 java.sql.Connection 对象,第二个语句将向单元格 b5 中返回一个 java.sql.ResultSet 对象。只需通过双击单元格 (b5) 就可检查结果集,该操作会将结果表显示在表格框架中以便查看。
迄今为止,我只在该电子表格中创建了几个简单的数据对象。现在,可以调用数据挖掘 API 来定义一个设置对象,然后创建一个简单的数据挖掘模型。首先,通过在单元格 b6 中输入以下语句来创建一个设置对象:
(*) = new cell.odm.OracleModelSettings("xyz_settings", b4,
new String[]{
"algo_name -> algo_support_vector_machines",
"svms_kernel_function -> svms_linear"} );
|
立刻我发现该公式中的问题是最终用户友好的,因此,注册一个带有 J Cells 的向导,在提示用户后自动生成该公式,可能是个不错的办法。一般,电子表格在用户创建复杂公式时都会给予帮助,因此用户可以期望在实例化对象时获得指导。
部署的向导如图 2 所示。
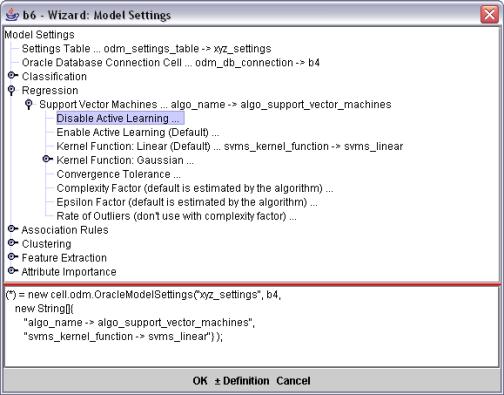
图 2:典型的向导界面
同样,数据挖掘模型通过使用向导或输入公式来创建,在这两种情况中,结果模型都是在直接指定 API 调用的单元格 b7 中进行实例化:
(*)= new cell.odm.OracleMiningModel("xyz_model", b6,
new String[]{
"data_table_name -> pulse_clinical",
"mining_function -> regression",
"target_column_name -> pulse",
"case_id_column_name -> subject"},
false );
|
使用该公式结果实例化数据挖掘模型将在 Oracle 数据库中生成标准的 Oracle 数据挖掘模型。该模型可通过双击单元格 b7 进行查看,模型的完整值如图 3 所示。
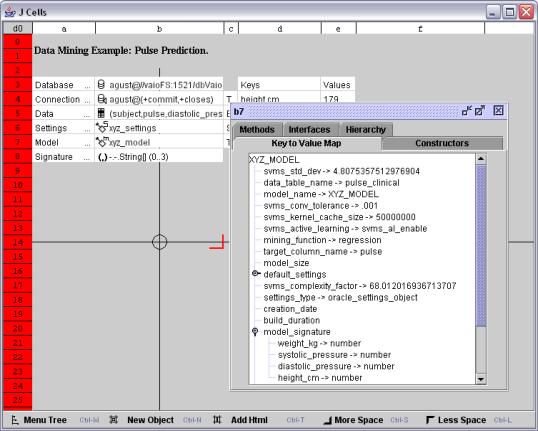
图 3:查看单元格 b7 中的模型
使用上述的 OracleMiningModel 方法,可将该模型应用到 Oracle 数据库中的数据集。作为一个简单的交互式评分模型(一般适用于电子表格应用程序),用户可能希望输入血压、高度和体重值,让数据库使用刚才定义的模型预测心率。这个在模型对象上定义的 Java API 方法 getPrediction 非常适合这一用途。在单元格 e4、e5、e6 以及 e7 中(以单元格 b8 中签名数组指定的顺序)键入输入值后,通过输入以下公式可进行评分:
(*) = b7.getPrediction(b8,new double[]{e4,e5,e6,e7});
同样,该公式将直接访问 Java API 以获取并在单元格 e9 中显示评分结果,如图 4 所示。
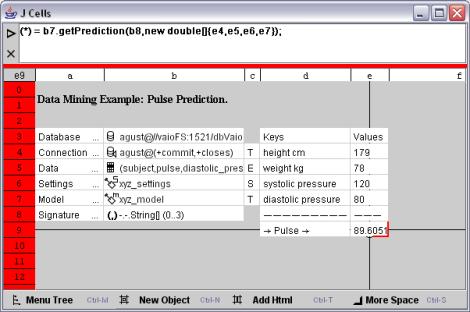
图 4:将模型应用到输入值
电子表格优点
电子表格在最终用户之间的流行多少有些令人费解。一方面,当今最常用的电子表格系统长期以来令许多开发人员气馁,他们习惯于更为灵活、强大的系统。而另一方面,对于非开发人员而言,使用电子表格系统具有以下一些明显优点:无须构建图形化用户界面、单独构建和测试每个公式(代码)以及隐藏公式,看到的是更为简单的计算结果。这些优点只存在于当今流行的电子表格中,使用公式可将数字或文本返回到单元格,而许多系统主要受限于此。此处演示了如何移除这一限制并创建更为强大的工具。然后用它来直接访问 Oracle 的数据挖掘模型功能以及其他 API。
结论
通过利用更为强大的电子表格,可以显著缩短向最终用户引入新技术版本(例如由发布的 Java API 和 PL/SQL API)的时间。事实上,使用此处的方法,直接将原始 Java API 交给非编程人员,以立即整合至决策制定流程或进行预测和分析是切实可行的。
【编辑推荐】












