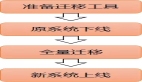
通常为了尽可能的减少对业务系统的压力和性能影响,或者因为网络传输异构数据库等原因,一般都是根据特定的增量抽取原则,将数据从业务数据库导出到flat文本文件或者XML文件中,也叫数据缓存区或者数据登台区(这名字起得特别别扭)。本文讨论的是从业务数据库直接抽取到数据仓库。数据仓库是一种体系架构,而不是一种纯粹的技术。实际上,大多数数据库都提供了类似的不同数据库直接连接的接口,例如SQL Server的链接数据库,Oracle的透明网关等等。
关于数据的增量抽取也是一个重要的讨论话题,其原因主要是在超大数据量情况下任何关系数据库都无法满足数据处理的要求。在《数据仓库》(Inmon)一书中,主要描述了以下3种方法:
1.数据增量抽取,主要是基于时间戳的;
2.扫描增量文件,实际上就是关系数据库的归档日志;
3.前后映像对比。
当然每种方法都有其优势和劣势,本文旨在讨论基于时间戳的数据增量抽取的实现,无意探讨和比较这三种方法的优劣。
当然在进行基于时间戳的数据增量处理之前,首先要满足以下假设:
1.假设在业务数据库中存在着一个特定的时间属性,作为增量抽取的唯一标识;
2.假设在这个字段上存在着索引字段。这样我们的数据增量抽取模拟脚本就不会遭遇到性能瓶颈。当然我们还会通过将大事务尽可能变成小事务的原则进行优化;
3.假设业务数据库和数据仓库能够以某种方式直接连接;
4.抽取过程中,尽量避免数据转换、清洗的动作,以减少对业务数据库的性能影响;
在满足了以上条件之后,我们才能进一步考虑数据增量抽取脚本的实现。

1.建立链接数据库;
2.首先需要定义一张数据字典表,定义需要进行处理的任务,其中主要包括业务数据库和目标数据库的表名、字段列表、以及where条件等;
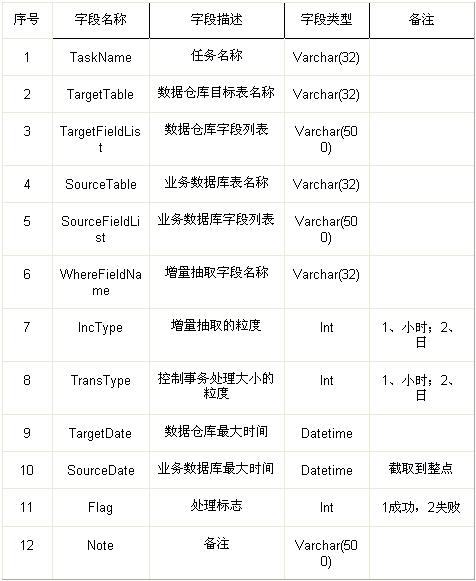
3.有了这张字典表就可以开始进行工作了,为了方便表达,暂时处理成伪代码形式,同时只以一个表的处理为例。
◆获取数据仓库目标表目前的***时间(读取字典表或者当前表均可)
◆获取业务数据库业务表目前的***时间(需要到业务系统中去读取)
◆如果业务数据库业务表数据为空,退出执行
◆如果数据仓库为空,业务数据库不为空,则再次读取业务数据库最小时时间
◆如果均不为空,则设置开始抽取最小时间和***时间
◆***时间设置为整点
◆根据控制事务处理大小的粒度,进行循环抽取
◆拼写SQL语句,写成类似以下的形式
INSERT INTO TargetTable (TargetFieldList) SELECT SourceFieldList FROM SourceTable WHERE WhereFieldName> BeginDate AND WhereFieldName< BeginDate+粒度 |
◆处理状态写入该字典表
4.有一点要主要的是,在SQL Server中有两种使用链接数据库的方法:
OPENQUERY ( linked_server , 'query' )
linked_server_name.catalog.schema.object_name的四部分名称
这两种方法各有利弊,第二种容易阅读一些;***种方法据说把语句提交到源数据库执行的,效率可能会高些(实际的资料并未找到)。
其次这两种方法在使用起来语法有点差别,***种方法采用的是宿主数据库的语法形式,第二种方法采用的是SQLServer本身的语法形式。因此在写脚本的时候也会有所不同。主要差别是在字段列表和条件处,暂时采用***种方式。
【编辑推荐】